
 全栈博客园
全栈博客园机器学习流程图一般用来描绘一个机器学习项目的过程和流程。以下是一个根本的机器学习流程图,包含了首要的过程:
1. 界说问题:明晰你要处理的具体问题,例如分类、回归、聚类等。
2. 搜集数据:依据问题搜集相关数据,这或许包含揭露数据集、API获取数据或自行搜集。
3. 数据预处理: 数据清洗:处理缺失值、异常值等。 特征工程:挑选或创立有助于模型猜测的特征。 数据转化:将数据转化为模型可以处理的格局,如归一化、标准化等。
4. 模型挑选:依据问题挑选适宜的机器学习算法,如线性回归、决策树、支撑向量机等。
5. 练习模型:运用练习数据集来练习模型,调整模型参数以优化功能。
6. 模型评价:运用验证集或测验集评价模型的功能,如准确率、召回率、F1分数等。
7. 模型优化:依据评价成果调整模型参数或测验不同的算法,以进步模型功能。
8. 模型布置:将练习好的模型布置到出产环境中,使其可以处理实时数据。
9. 监控和保护:定时监控模型的功能,并依据需求进行调整或更新。
请注意,这仅仅一个根本的机器学习流程图,实践的机器学习项目或许会愈加杂乱,包含更多的过程和细节。
机器学习流程图:概述
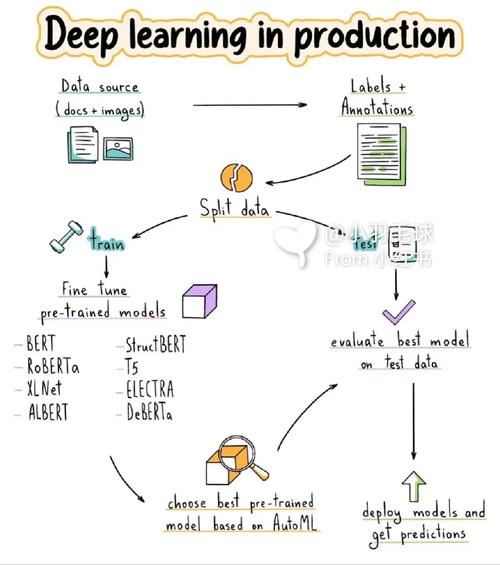
在当今数据驱动的国际中,机器学习已经成为许多职业的关键技术。为了更好地了解和施行机器学习项目,一个明晰的流程图对错常有协助的。本文将具体介绍机器学习流程图,包含其各个阶段和关键过程。
一、问题界说
在开端任何机器学习项目之前,首要需求明晰问题的界说。这一阶段触及对问题的深化了解,包含问题的布景、方针以及所需处理的问题。
1.1 问题布景
了解问题的布景关于确认处理方案至关重要。这包含问题的来历、影响以及为什么需求处理这个问题。
1.2 方针设定
明晰方针可以协助团队集中精力,保证一切尽力都朝着同一个方向行进。方针可以是猜测、分类、聚类或其他类型的使命。
1.3 问题剖析
对问题进行具体剖析,确认问题的性质、数据可用性以及或许的处理方案。
二、数据搜集与预处理
数据是机器学习项目的柱石。在这一阶段,需求搜集相关数据,并进行预处理以消除噪声和异常值。
2.1 数据搜集
依据问题界说,搜集必要的数据。这或许触及从数据库、文件或网络中提取数据。
2.2 数据清洗
清洗数据以去除重复项、缺失值和异常值。这有助于进步模型的准确性和可靠性。
2.3 数据转化
将数据转化为适宜机器学习算法的格局。这或许包含归一化、标准化或特征工程。
三、探索性数据剖析
在预处理数据后,进行探索性数据剖析(EDA)以了解数据的散布和特征。
3.1 数据可视化
运用图表和图形来展现数据的散布和趋势,协助辨认数据中的形式。
3.2 核算剖析
运用核算方法来剖析数据,如核算均值、方差、相关性等。
3.3 特征挑选
依据数据剖析成果,挑选对模型功能有重要影响的特征。
四、模型挑选与练习
挑选适宜的机器学习模型,并运用练习数据对其进行练习。
4.1 模型挑选
依据问题的性质和数据的特色,挑选适宜的算法。常见的算法包含线性回归、决策树、支撑向量机、神经网络等。
4.2 模型练习
运用练习数据对选定的模型进行练习,调整模型参数以优化功能。
4.3 超参数调优
调整模型中的超参数,如学习率、迭代次数等,以进一步进步模型功能。
五、模型评价与优化
评价模型的功能,并依据评价成果进行优化。
5.1 评价目标
挑选适宜的评价目标,如准确率、召回率、F1分数等,以衡量模型功能。
5.2 功能剖析
剖析模型的功能,辨认或许的改善点。
5.3 模型优化
依据功能剖析成果,对模型进行调整和优化。
六、模型布置与监控

将练习好的模型布置到实践运用中,并对其进行监控和保护。
6.1 模型布置
将模型集成到运用程序中,使其可以处理实践数据。
6.2 模型监控
监控模型的功能,保证其安稳运转。
6.3 模型更新
依据新数据或用户反应,对模型进行更新和改善。
机器学习流程图是一个系统化的结构,协助咱们从问题界说到模型布置的
 百变机器学习,探究人工智能的无限或许
百变机器学习,探究人工智能的无限或许 神经网络与机器学习,探究智能年代的核心技能
神经网络与机器学习,探究智能年代的核心技能 机器学习吴恩达笔记,浅显易懂吴恩达机器学习笔记——敞开AI学习之旅
机器学习吴恩达笔记,浅显易懂吴恩达机器学习笔记——敞开AI学习之旅 形式辨认与机器学习,技能交融与未来展望
形式辨认与机器学习,技能交融与未来展望 机器学习 mobi
机器学习 mobi ai归纳点评办法,全面解析与未来展望
ai归纳点评办法,全面解析与未来展望 48ai归纳,探究人工智能在各个范畴的使用与应战
48ai归纳,探究人工智能在各个范畴的使用与应战 机器人课程学习,敞开未来科技之旅
机器人课程学习,敞开未来科技之旅











