
 全栈博客园
全栈博客园大数据剖析是一个触及多个范畴的杂乱进程,包含数据搜集、存储、处理、剖析和解说。Python 是进行大数据剖析的一种十分盛行的编程言语,由于它具有强壮的数据处理库和东西,例如 Pandas、NumPy、SciPy、Scikitlearn、TensorFlow 和 PyTorch。下面我将介绍一些运用 Python 进行大数据剖析的根本过程和东西:
1. 数据搜集:首要,需求搜集数据。数据能够来自各种来历,如数据库、API、Web 爬虫、传感器等。Python 供给了多种库来协助搜集数据,例如 `requests` 用于从 Web API 获取数据,`pandas` 用于读取和写入各种文件格局,`BeautifulSoup` 和 `Scrapy` 用于 Web 爬虫等。
2. 数据存储:搜集到的数据需求存储在恰当的当地,以便于后续处理和剖析。Python 支撑多种数据存储解决方案,包含联系型数据库(如 MySQL、PostgreSQL)、非联系型数据库(如 MongoDB、Cassandra)以及数据湖(如 Hadoop HDFS、Amazon S3)等。
3. 数据处理:在剖析数据之前,一般需求对数据进行清洗和预处理。这包含处理缺失值、异常值、重复值,以及进行数据转化、归一化等。Pandas 是 Python 中用于数据处理的首要库,它供给了丰厚的数据结构和数据剖析东西。
5. 数据可视化:数据剖析的成果一般需求经过可视化来展现,以便于更好地了解和解说。Python 供给了多种数据可视化库,如 `Matplotlib`、`Seaborn`、`Bokeh`、`Plotly` 和 `ggplot`(经过 `plotnine` 库)。
6. 机器学习和深度学习:关于更杂乱的数据剖析使命,如猜测建模、分类、聚类等,能够运用机器学习和深度学习技能。Python 供给了多种机器学习和深度学习库,如 `Scikitlearn`、`TensorFlow`、`Keras`、`PyTorch` 和 `MXNet`。
7. 数据陈述和展现:需求将数据剖析的成果以陈述或展现的方式出现给决策者或相关利益相关者。Python 供给了多种东西来生成陈述和展现,如 `Jupyter Notebook`、`JupyterLab`、`Dash`、`Streamlit` 和 `Qlik Sense`。
8. 数据安全和隐私:在进行大数据剖析时,需求保证数据的安全和隐私。Python 供给了多种东西来维护数据,如 `cryptography`、`PyCryptodome` 和 `SQLAlchemy`。
9. 功用优化:关于大规模数据集,或许需求优化代码以取得更好的功用。Python 供给了多种东西来优化代码,如 `Numba`、`Cython` 和 `PyPy`。
10. 协作和版别操控:在进行大数据剖析项目时,协作和版别操控是十分重要的。Python 项目一般运用 Git 进行版别操控,并运用 GitHub、GitLab 或 Bitbucket 作为代码保管渠道。
以上是运用 Python 进行大数据剖析的一些根本过程和东西。请注意,这仅仅一个概述,实践的大数据剖析项目或许会愈加杂乱,需求依据详细的需求和场景挑选适宜的东西和技能。
Python大数据剖析:技能解析与实战事例

一、Python大数据剖析概述

Python大数据剖析首要依赖于以下几个库:NumPy、Pandas、Matplotlib、Scikit-learn等。这些库为Python供给了强壮的数据处理和剖析功用,使得Python成为大数据剖析范畴的首选言语。
二、NumPy:高效数值核算
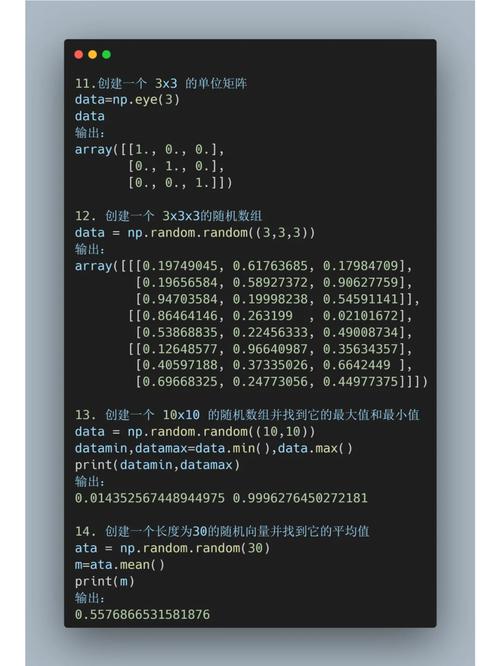
NumPy是Python中用于数值核算的库,它供给了强壮的多维数组目标和一系列数学函数。NumPy在Python大数据剖析中扮演着重要人物,能够高效地进行数据存储、核算和操作。
以下是一个运用NumPy进行数值核算的示例:
```python
import numpy as np
创立一个一维数组
array = np.array([1, 2, 3, 4, 5])
核算数组元素之和
sum_array = np.sum(array)
输出成果
print(\
未经允许不得转载:全栈博客园 » python大数据剖析,技能解析与实战事例
 大数据用什么数据库,大数据年代数据库的挑选重要性
大数据用什么数据库,大数据年代数据库的挑选重要性 excel导入mysql,Excel数据导入MySQL数据库的具体攻略
excel导入mysql,Excel数据导入MySQL数据库的具体攻略 oracle树立用户,Oracle数据库中树立用户详解
oracle树立用户,Oracle数据库中树立用户详解 生物信息学数据库,探究生命奥妙的数字宝库
生物信息学数据库,探究生命奥妙的数字宝库 大数据运用的事例,怎么运用大数据技能前进企业竞争力
大数据运用的事例,怎么运用大数据技能前进企业竞争力










