
 全栈博客园
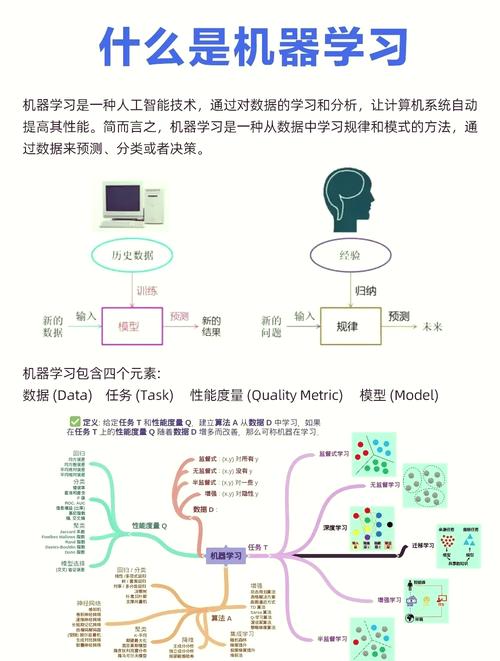
全栈博客园机器学习中的文本分类是一种将文本数据归类到预界说类别中的使命。这种技能广泛运用于许多范畴,如垃圾邮件过滤、情感剖析、新闻分类、客户反应剖析等。文本分类的根本流程一般包含以下进程:
1. 数据搜集:搜集很多的文本数据,这些数据将用于练习和测验模型。2. 数据预处理:对文本数据进行清洗和格局化,这或许包含去除停用词、标点符号、数字、特别字符,以及进行词干提取或词形复原等。3. 特征提取:将文本数据转换为机器学习模型能够了解的格局。常用的特征提取办法包含词袋模型(Bag of Words)、TFIDF(词频逆文档频率)、词嵌入(Word Embeddings)等。4. 模型练习:运用练习数据来练习一个或多个分类模型。常见的分类算法有朴素贝叶斯、支撑向量机(SVM)、决议计划树、随机森林、神经网络等。5. 模型评价:运用测验数据来评价模型的功能,常用的评价方针包含精确率、召回率、F1分数等。6. 模型布置:将练习好的模型布置到出产环境中,用于对新文本数据进行分类。
在文本分类使命中,机器学习模型的方针是学习文本数据中的形式,以便能够精确地猜测文本数据的类别。这一般涉及到对很多文本数据进行迭代学习,以优化模型参数,然后进步分类精确性。跟着技能的不断进步,深度学习在文本分类范畴也取得了明显的作用,特别是根据循环神经网络(RNN)和Transformer架构的模型,如BERT、GPT等,它们能够捕捉文本中的长距离依靠联系,并展现出强壮的文本了解能力。
机器学习在文本分类中的运用:技能解析与未来展望
一、文本分类概述
文本分类是指将文本数据依照必定的规范进行归类,以便于后续的检索、剖析和处理。常见的文本分类使命包含情感剖析、垃圾邮件检测、主题分类等。文本分类的关键在于怎么提取文本特征,并构建有用的分类模型。
二、机器学习在文本分类中的运用

机器学习技能在文本分类中的运用首要包含以下几个方面:
1. 特征提取
特征提取是文本分类的根底,常用的特征提取办法包含:
词袋模型(Bag of Words,BoW):将文本表明为单词的调集,疏忽单词的次序。
TF-IDF(Term Frequency-Inverse Document Frequency):考虑单词在文档中的频率和在整个文档会集的逆频率,以反映单词的重要性。
词嵌入(Word Embedding):将单词映射到高维空间,以捕捉单词的语义信息。
2. 分类算法
根据特征提取的作用,能够运用以下分类算法进行文本分类:
朴素贝叶斯(Naive Bayes):根据贝叶斯定理,经过核算文本归于某个类其他概率进行分类。
支撑向量机(Support Vector Machine,SVM):经过寻觅最优的超平面将不同类其他数据点分隔。
决议计划树(Decision Tree):经过一系列的决议计划规矩对文本进行分类。
随机森林(Random Forest):集成学习算法,经过构建多个决议计划树进行分类。
深度学习:使用神经网络对文本进行分类,如卷积神经网络(CNN)和循环神经网络(RNN)。
3. 模型评价
在文本分类使命中,常用的模型评价方针包含精确率、召回率、F1值等。经过比照不同模型的功能,能够选出最优的分类模型。
三、机器学习在文本分类中的应战与展望
虽然机器学习技能在文本分类范畴取得了明显作用,但仍面对以下应战:
1. 数据质量
文本数据质量对分类作用有重要影响。在实践运用中,需求处理噪声数据、缺失数据和异常值等问题。
2. 特征工程
特征工程是文本分类的关键环节,但特征工程进程杂乱,且对范畴常识要求较高。
3. 模型可解说性
深度学习模型在文本分类中表现出色,但其内部机制杂乱,难以解说。
针对以上应战,未来机器学习在文本分类范畴的发展趋势如下:
数据增强:经过数据增强技能进步数据质量,如数据清洗、数据扩大等。
主动特征提取:使用深度学习技能完成主动特征提取,下降特征工程难度。
可解说性研讨:进步模型可解说性,使模型更易于了解和运用。
机器学习技能在文本分类范畴取得了明显作用,但仍面对许多应战。跟着技能的不断发展,信任机器学习在文本分类范畴的运用将愈加广泛,为各行各业带来更多价值。
未经允许不得转载:全栈博客园 » 机器学习 文本分类,技能解析与未来展望
 ai识图,革新视觉辨认的未来
ai识图,革新视觉辨认的未来 巴黎归纳理工ai,AI范畴的前锋力气
巴黎归纳理工ai,AI范畴的前锋力气 ai se 归纳,推进工业革新与立异
ai se 归纳,推进工业革新与立异 机器学习大牛,那些改动世界的“大牛”们
机器学习大牛,那些改动世界的“大牛”们 机器学习的进程,机器学习进程概述
机器学习的进程,机器学习进程概述 ai资料,立异内容创造的得力助手
ai资料,立异内容创造的得力助手 机器学习程序,从入门到实践
机器学习程序,从入门到实践 机器学习与大数据实战,从理论到使用的跨过
机器学习与大数据实战,从理论到使用的跨过












