
 全栈博客园
全栈博客园1. 准确率(Accuracy):准确率是分类问题中最常用的目标,表明模型正确猜测的样本数量占总样本数量的份额。计算公式为: $$ text{准确率} = frac{text{正确猜测的样本数量}}{text{总样本数量}} $$
2. 准确率(Precision):准确率是评价模型在猜测正类时的准确程度。它表明在模型猜测为正类的样本中,实践为正类的样本所占的份额。计算公式为: $$ text{准确率} = frac{text{实在例}}{text{实在例} text{假正例}} $$
3. 召回率(Recall):召回率是评价模型在猜测正类时的召回才能。它表明在一切实践为正类的样本中,模型正确猜测为正类的样本所占的份额。计算公式为: $$ text{召回率} = frac{text{实在例}}{text{实在例} text{假负例}} $$
4. F1 分数(F1 Score):F1 分数是准确率和召回率的谐和平均数,用于归纳评价模型在分类问题上的体现。计算公式为: $$ text{F1 分数} = 2 times frac{text{准确率} times text{召回率}}{text{准确率} text{召回率}} $$
5. 均方差错(Mean Squared Error, MSE):均方差错是回归问题中最常用的目标,表明模型猜测值与实践值之间差的平方的平均值。计算公式为: $$ text{MSE} = frac{1}{n} sum_{i=1}^{n} ^2 $$ 其间,$ n $ 是样本数量,$ y_i $ 是实践值,$ hat{y}_i $ 是模型猜测值。
6. 均方根差错(Root Mean Squared Error, RMSE):均方根差错是均方差错的平方根,它供给了对猜测差错的直观了解。计算公式为: $$ text{RMSE} = sqrt{text{MSE}} $$
7. 均绝对差错(Mean Absolute Error, MAE):均绝对差错是回归问题中的另一个常用目标,表明模型猜测值与实践值之间差的绝对值的平均值。计算公式为: $$ text{MAE} = frac{1}{n} sum_{i=1}^{n} |y_i hat{y}_i| $$
8. R2 分数(R2 Score):R2 分数,也称为决定系数,是回归问题中的另一个常用目标,表明模型对数据的拟合程度。计算公式为: $$ text{R2 分数} = 1 frac{text{RSS}}{text{TSS}} $$ 其间,RSS 是残差平方和,TSS 是总平方和。
9. AUC(Area Under the ROC Curve):AUC 是评价二分类模型功能的目标,表明 ROC 曲线下方的面积。AUC 值越大,模型的功能越好。
10. 混杂矩阵(Confusion Matrix):混杂矩阵是评价分类问题中模型功能的表格,它展现了模型猜测为正类和负类的样本数量,以及实践为正类和负类的样本数量。混杂矩阵中的元素包含实在例(TP)、假正例(FP)、假负例(FN)和真负例(TN)。
这些目标能够依据详细的问题和需求进行挑选和运用。在实践使用中,一般需求归纳考虑多个目标来全面评价模型的功能。
机器学习目标:评价模型功能的要害东西

在机器学习范畴,评价模型功能是至关重要的过程。经过适宜的目标,咱们能够了解模型在特定使命上的体现,然后进行优化和改善。本文将介绍几种常用的机器学习目标,协助读者更好地了解怎么评价模型功能。
1. 准确率(Precision)

准确率是衡量模型猜测成果中正确猜测的份额。其计算公式为:准确率 = TP / (TP FP),其间TP代表实在例(True Positive),FP代表假正例(False Positive)。准确率越高,阐明模型在猜测正例时越准确。
2. 召回率(Recall)
召回率是指模型猜测成果中正确猜测的正例占一切实践正例的份额。其计算公式为:召回率 = TP / (TP FN),其间FN代表假反例(False Negative)。召回率越高,阐明模型在猜测正例时越全面。
3. F1 分数(F1 Score)

F1 分数是准确率和召回率的谐和平均数,用于平衡两者之间的联系。其计算公式为:F1 分数 = 2 (准确率 召回率) / (准确率 召回率)。F1 分数越高,阐明模型在准确率和召回率之间取得了较好的平衡。
4. 实在例率(True Positive Rate,TPR)
实在例率是指模型猜测成果中正确猜测的正例占一切实践正例的份额。其计算公式为:TPR = TP / (TP FN)。实在例率越高,阐明模型在猜测正例时越准确。
5. 假正例率(False Positive Rate,FPR)
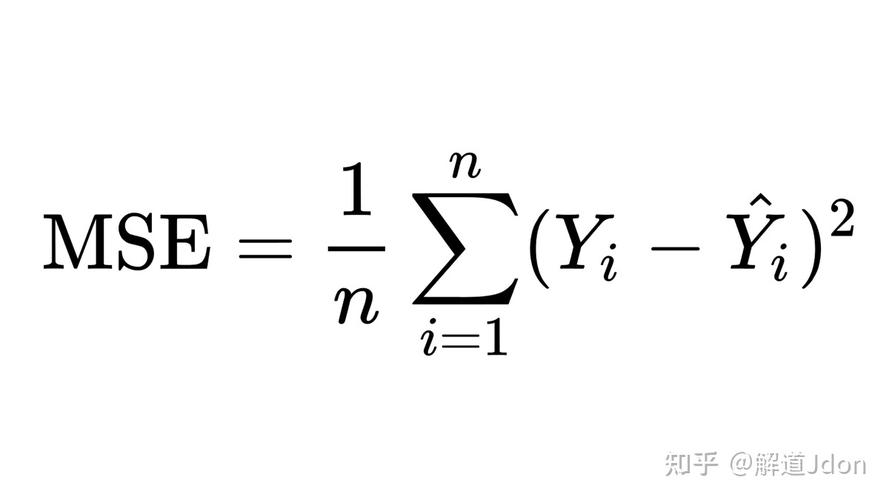
假正例率是指模型猜测成果中过错猜测的正例占一切实践负例的份额。其计算公式为:FPR = FP / (FP TN),其间TN代表真反例(True Negative)。假正例率越低,阐明模型在猜测负例时越准确。
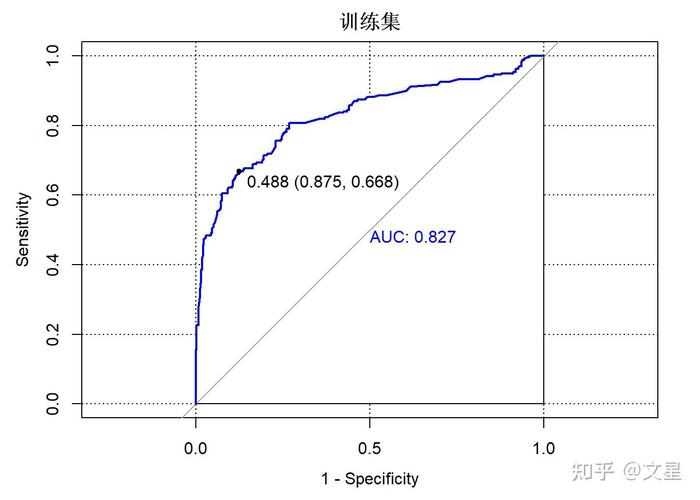
6. ROC 曲线与 AUC
ROC 曲线(Receiver Operating Characteristic Curve)是一种经过制作实在例率(TPR)与假正例率(FPR)来评价分类模型功能的图形东西。AUC(Area Under the Curve)是 ROC 曲线下的面积,取值规模为 0 到 1。AUC 越高,阐明模型在区别正负例时越有用。
7. 准确率-召回率曲线与 AUPRC
准确率-召回率曲线(Precision-Recall Curve)经过制作查准率(Precision)与召回率(Recall)来评价模型功能。AUPRC(Area Under the Precision-Recall Curve)是准确率-召回率曲线下的面积,取值规模为 0 到 1。AUPRC 越高,阐明模型在处理不平衡数据时越有用。
8. 均方差错(MSE)
均方差错(Mean Squared Error,MSE)是一种常用的回归问题评价目标,用于衡量模型猜测值与实在值之间的差错程度。MSE 值越小,阐明模型猜测的成果与实在值越挨近。
9. 均方根差错(RMSE)
均方根差错(Root Mean Squared Error,RMSE)是均方差错的平方根,用于衡量模型猜测值与实在值之间的差错程度。RMSE 值越小,阐明模型猜测的成果与实在值越挨近。
在机器学习范畴,了解和运用各种目标关于评价模型功能至关重要。本文介绍了常用的机器学习目标,包含准确率、召回率、F1 分数、实在例率、假正例率、ROC 曲线与 AUC、准确率-召回率曲线与 AUPRC、均方差错和均方根差错。经过合理运用这些目标,咱们能够更好地评价和优化机器学习模型。
未经允许不得转载:全栈博客园 » 机器学习目标,评价模型功能的要害东西
 天天AI归纳,探究人工智能的无限或许
天天AI归纳,探究人工智能的无限或许 机器学习数据剖析,从数据到洞悉的桥梁
机器学习数据剖析,从数据到洞悉的桥梁 松鼠ai智习惯,引领教育革新,打造个性化学习新体会
松鼠ai智习惯,引领教育革新,打造个性化学习新体会 线性代数和机器学习,线性代数的基本概念
线性代数和机器学习,线性代数的基本概念 归纳图片生成ai,立异与革新的交汇点
归纳图片生成ai,立异与革新的交汇点 特殊归纳8p欢迎ai,AI年代的机会与应战
特殊归纳8p欢迎ai,AI年代的机会与应战 化学品AI归纳,人工智能在化学品范畴的归纳运用与未来展望
化学品AI归纳,人工智能在化学品范畴的归纳运用与未来展望











