
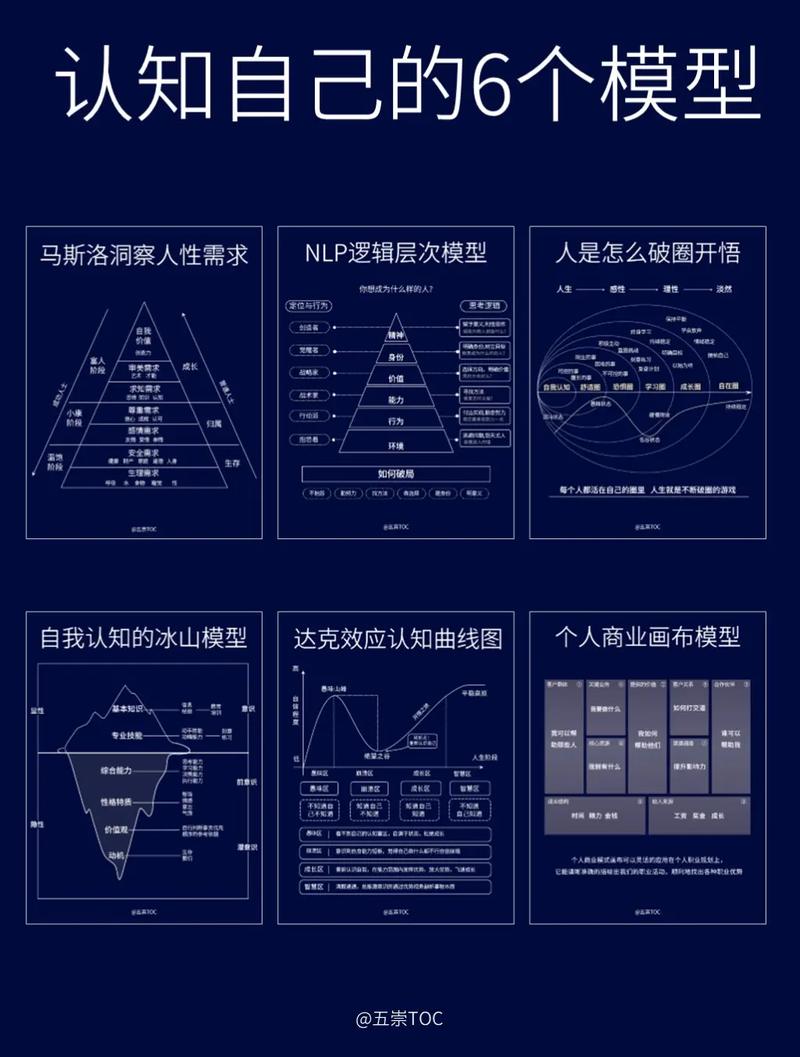
 全栈博客园
全栈博客园机器学习中的归一化(Normalization)是一种预处理技能,用于调整数据集的特征值,使其具有相同的标准或散布。归一化在机器学习中非常重要,由于它能够协助模型更好地学习,防止某些特征由于其数值规模较大而主导模型的学习进程。
归一化一般分为两种类型:线性归一化和非线性归一化。
1. 线性归一化:将数据特征缩放到一个固定规模,一般是或。常见的线性归一化办法包含: 最小最大归一化(MinMax Normalization):将特征值缩放到或规模。 Zscore归一化(Zscore Normalization):将特征值缩放到均值为0,标准差为1的散布。
2. 非线性归一化:将数据特征缩放到特定的散布,如正态散布。常见的非线性归一化办法包含: 对数归一化(Log Normalization):将特征值取对数,适用于数值规模较大的数据。 标准化(Standardization):将特征值缩放到均值为0,标准差为1的散布,但不改动其原始散布。
在机器学习中,归一化能够带来以下优点:1. 进步模型的泛化才能:归一化能够下降模型对特征标准灵敏性的影响,进步模型的泛化才能。2. 加速模型的收敛速度:归一化能够加速模型的学习速度,由于模型不需求在特征标准上进行调整。3. 防止数值安稳性问题:归一化能够防止由于特征标准差异导致的数值安稳性问题,如梯度爆破或梯度消失。
归一化也或许带来一些问题:1. 信息丢掉:归一化或许丢掉某些特征的信息,特别是当特征值具有特定意义时。2. 对异常值的灵敏:归一化或许对异常值灵敏,由于异常值或许会对归一化进程产生较大影响。
因而,在运用归一化时,需求依据具体问题挑选适宜的归一化办法,并留意归一化或许带来的问题。
机器学习中的归一化:进步模型功能的关键过程
在机器学习中,数据预处理是一个至关重要的过程,它直接影响着模型的功能和泛化才能。归一化(Normalization)是数据预处理中的一个重要环节,它经过调整数据散布,使得不同特征之间的数值巨细变得可比,然后进步模型的练习功率和准确性。本文将深入探讨归一化的概念、办法及其在机器学习中的运用。
什么是归一化?
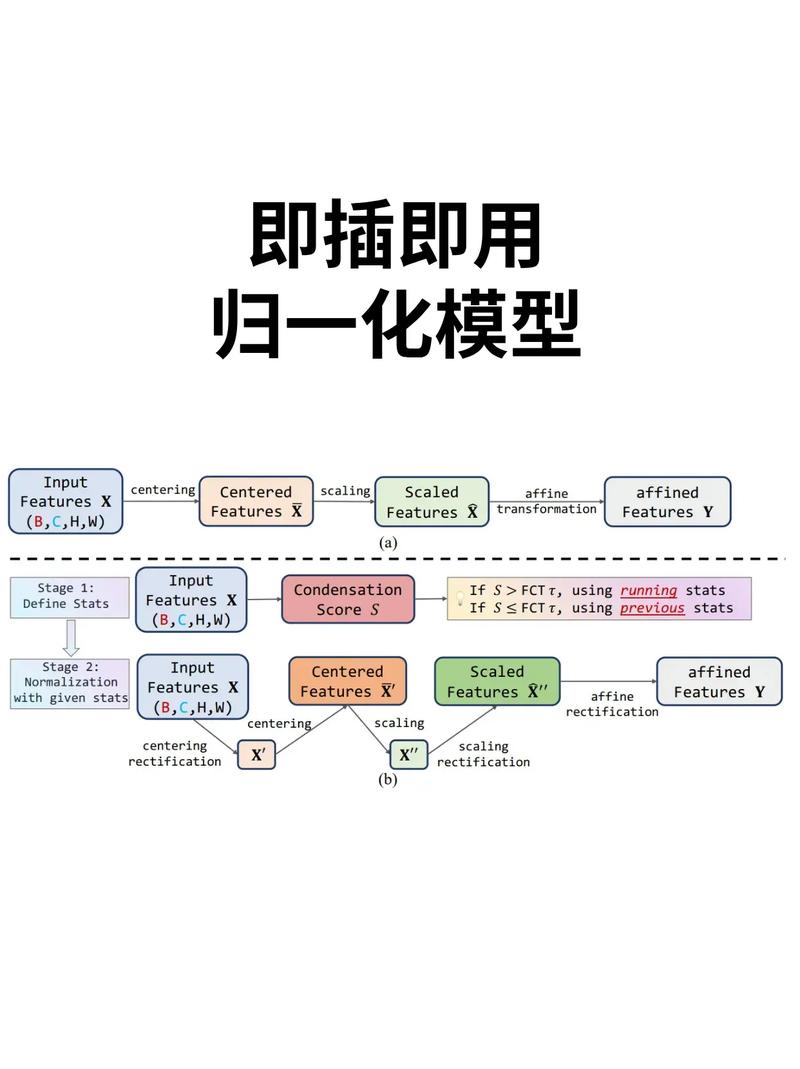
界说

归一化是指将数据缩放到一个特定的规模,一般是[0, 1]或[-1, 1],以便于模型处理。归一化的意图是消除不同特征之间的标准差异,使得每个特征在模型练习中具有相同的权重。
原因

在实践国际中,不同特征的数据量级或许相差很大。例如,年纪和收入这两个特征,年纪一般以年为单位,而收入或许以万元为单位。假如直接将这些特征输入到模型中,或许会导致模型在练习进程中对某些特征赋予过大的权重,然后影响模型的功能。
归一化的办法

最小-最大归一化
最小-最大归一化(Min-Max Normalization)是一种常见的归一化办法,它将数据缩放到[0, 1]或[-1, 1]的规模。公式如下:
\\[ X_{\\text{norm}} = \\frac{X - X_{\\text{min}}}{X_{\\text{max}} - X_{\\text{min}}} \\]
其间,\\( X \\) 是原始数据,\\( X_{\\text{min}} \\) 和 \\( X_{\\text{max}} \\) 分别是特征的最小值和最大值。
Z-Score标准化
Z-Score标准化(Z-Score Normalization)也称为均值-标准差标准化,它将数据转换为均值为0、标准差为1的散布。公式如下:
\\[ X_{\\text{norm}} = \\frac{X - \\mu}{\\sigma} \\]
其间,\\( \\mu \\) 是特征的平均值,\\( \\sigma \\) 是特征的标准差。
小数归一化
小数归一化(Decimal Scaling)是一种简略且有用的归一化办法,它经过乘以10的幂来调整数据的巨细。公式如下:
\\[ X_{\\text{norm}} = X \\times 10^{\\text{scale}} \\]
其间,\\( \\text{scale} \\) 是一个正整数,用于确认数据的巨细。
归一化在机器学习中的运用
进步模型功能
归一化能够明显进步模型的功能,尤其是在运用梯度下降等优化算法时。归一化后的数据能够加速模型的收敛速度,进步模型的准确性和泛化才能。
防止数值不安稳
在核算进程中,假如数据量级相差很大,或许会导致数值不安稳,然后影响模型的练习。归一化能够防止这种状况的产生。
进步模型的可解释性
归一化后的数据使得不同特征之间的数值巨细变得可比,有助于了解模型对各个特征的灵敏程度。
归一化是机器学习中一个重要的数据预处理过程,它经过调整数据散布,消除不同特征之间的标准差异,然后进步模型的功能和泛化才能。在实践运用中,应依据具体问题和数据特色挑选适宜的归一化办法。
 能做ppt的ai,智能化年代的新挑选
能做ppt的ai,智能化年代的新挑选 吴恩达Cousera机器学习课程,敞开人工智能学习之旅
吴恩达Cousera机器学习课程,敞开人工智能学习之旅 ai家具归纳城,未来家居购物的新趋势
ai家具归纳城,未来家居购物的新趋势 儿童学习编程机器人,敞开未来智能之门
儿童学习编程机器人,敞开未来智能之门 ai全称,人工智能的全面知道
ai全称,人工智能的全面知道 机器学习书面考试,全面解析常见题型与应对战略
机器学习书面考试,全面解析常见题型与应对战略 机器学习 豆瓣,机器学习在豆瓣电影引荐体系中的运用
机器学习 豆瓣,机器学习在豆瓣电影引荐体系中的运用











