
 全栈博客园
全栈博客园小样本学习(Fewshot learning)是机器学习的一个分支,首要研讨的是怎么让模型在仅有少数样本的情况下,快速学习并泛化到新的使命中。在传统的监督学习使命中,模型一般需求许多的标示样原本进行练习,而在小样本学习使命中,模型需求具有快速习惯新使命的才能,即经过学习少数的样本,可以对新样本进行分类、回归或其他使命。
小样本学习一般包含以下几个关键过程:
1. 数据增强:经过数据增强技能,如旋转、缩放、裁剪等,添加练习样本的多样性,进步模型的泛化才能。
2. 特征提取:使用深度学习等技能提取样本的特征,使得特征可以更好地表明样本的本质属性。
3. 衡量学习:经过衡量学习(Metric Learning)技能,学习样本之间的类似度衡量,使得同类样本之间的间隔更小,不同类样本之间的间隔更大。
4. 模型挑选:挑选适宜的模型,如支撑向量机(SVM)、神经网络等,来学习样本的特征和类似度衡量。
5. 练习与优化:使用少数样本对模型进行练习,并经过优化算法(如梯度下降)来调整模型的参数,进步模型的功能。
6. 评价与测验:经过评价方针(如精确率、召回率等)来评价模型的功能,并在测验集上测验模型的泛化才能。
小样本学习在许多范畴都有广泛的使用,如核算机视觉、自然语言处理、语音辨认等。经过小样本学习技能,可以削减数据标示的工作量,进步模型的泛化才能,为实践使用供给更好的处理方案。
小样本机器学习:打破数据约束,进步模型泛化才能
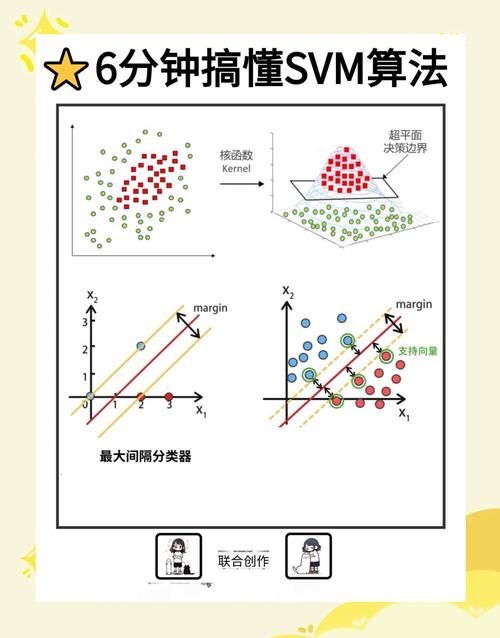
一、小样本机器学习的布景与含义

在实际国际中,因为数据搜集本钱高、隐私维护等要素,许多场景下咱们只能取得少数样本。例如,在医疗确诊、金融风控、智能引荐等范畴,往往需求针对特定个别或特定场景进行模型练习,而这些场景下的数据往往有限。小样本机器学习正是为了处理这类问题而诞生的。
小样本机器学习的含义在于:
下降数据搜集本钱:在数据稀缺的情况下,小样本机器学习可以削减对许多数据的依靠,然后下降数据搜集本钱。
进步模型泛化才能:经过使用有限的样本和先验常识,小样本机器学习可以进步模型的泛化才能,使其在面临新数据时可以做出精确的猜测。
拓宽机器学习使用场景:小样本机器学习可以使用于更多数据稀缺的场景,推进人工智能技能在各个范畴的使用。
二、小样本机器学习的基本原理

小样本机器学习的基本原理是使用有限的样本和先验常识,经过以下过程完成模型的泛化才能:
特征提取:从有限的样本中提取出有用的特征,为后续学习供给根底。
模型练习:使用提取出的特征和先验常识,对模型进行练习,使其可以辨认和分类样本。
模型评价:经过测验集评价模型的泛化才能,保证模型在面临新数据时可以做出精确的猜测。
三、小样本机器学习的首要办法
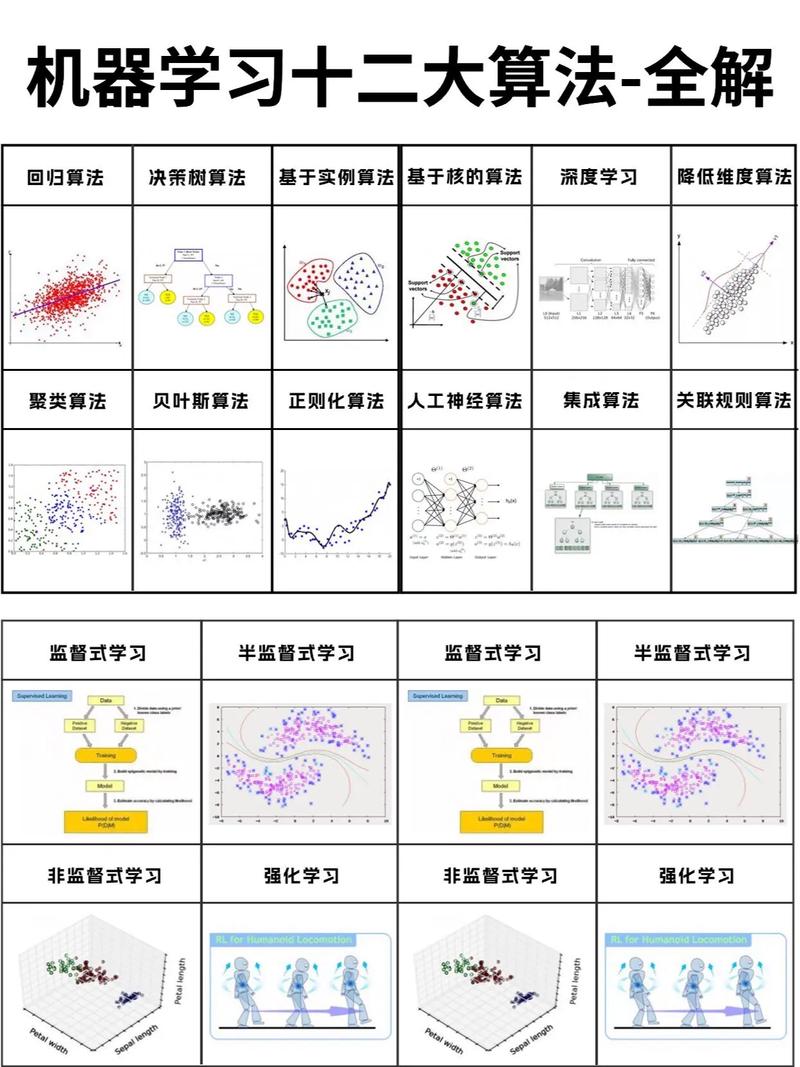
现在,小样本机器学习首要分为以下几种办法:
1. 根据搬迁学习的办法
搬迁学习是一种将已有常识搬迁到新使命上的办法。在小样本机器学习中,可以经过搬迁学习将已有范畴的常识搬迁到方针范畴,然后进步模型的泛化才能。
2. 根据原型网络的办法
原型网络是一种根据间隔衡量的分类办法。在小样本机器学习中,可以经过原型网络学习到样本的代表性特征,然后进步模型的分类才能。
3. 根据孪生网络的办法
孪生网络是一种根据对立学习的分类办法。在小样本机器学习中,可以经过孪生网络学习到样本的代表性特征,然后进步模型的分类才能。
4. 根据元学习的办法
元学习是一种经过学习怎么学习的办法。在小样本机器学习中,可以经过元学习使模型可以快速习惯新使命,然后进步模型的泛化才能。
四、小样本机器学习的应战与展望
虽然小样本机器学习取得了必定的作用,但仍面临以下应战:
数据稀缺:在数据稀缺的情况下,怎么有用地提取特征和使用先验常识成为了一个难题。
模型泛化才能:怎么进步模型的泛化才能,使其在面临新数据时可以做出精确的猜测,仍是一个亟待处理的问题。
算法复杂度:小样本机器学习算法往往具有较高的复杂度,怎么下降算法复杂度,进步核算功率,也是一个应战。
未来,小样本机器学习的研讨方向首要包含:
探究更有用的特征提取办法,进步模型的泛化才能。
研讨新的算法,下降算法复杂度,进步核算功率。
结合其他机器学习技能,如深度学习、强化学习等,进一步进步小样本机器学习的作用。
小样本机器学习作为一种新式的机器学习办法,在数据稀缺的情况下具有广泛的使用远景。经过不断探究和研讨,小样本机器学习有望在各个范畴发挥重要作用,推进人工智能技能的开展。
未经允许不得转载:全栈博客园 » 小样本机器学习,打破数据约束,进步模型泛化才能
 ai生成图片软件免费,构思无限,轻松上手
ai生成图片软件免费,构思无限,轻松上手 人工ai,未来日子的革新者
人工ai,未来日子的革新者 AI编程,未来技能浪潮中的编程新篇章
AI编程,未来技能浪潮中的编程新篇章 ai归纳帮手app,AI归纳帮手APP——智能日子新同伴
ai归纳帮手app,AI归纳帮手APP——智能日子新同伴 ai阅读器,互联网年代的改造者
ai阅读器,互联网年代的改造者 ai算法,驱动未来智能化的中心力气
ai算法,驱动未来智能化的中心力气 好记星学习机器人,智能教育的新同伴
好记星学习机器人,智能教育的新同伴 我国归纳AI换脸,我国AI换脸技能开展与运用现状
我国归纳AI换脸,我国AI换脸技能开展与运用现状










