
 全栈博客园
全栈博客园机器学习根底笔记可以分为以下几个部分:
2. 监督学习 分类问题:猜测输出为离散值,如二分类(垃圾邮件检测)或多分类(图像辨认)。 回归问题:猜测输出为接连值,如房价猜测。
3. 无监督学习 聚类:将数据分红不同的组,每组内部相似度较高,组间相似度较低。 降维:将高维数据转化为低维数据,一起保存尽可能多的信息。
4. 常用算法 线性回归:用于回归问题,树立线性关系。 逻辑回归:用于二分类问题,经过Sigmoid函数输出概率。 决议计划树:用于分类和回归问题,经过树状结构进行决议计划。 支撑向量机(SVM):用于分类和回归问题,经过找到最大距离的超平面进行分类。 随机森林:集成学习办法,结合多个决议计划树进行猜测。 神经网络:模仿人脑神经元结构,用于复杂问题,如图像辨认、自然语言处理。
5. 模型评价 准确率:正确猜测的份额。 召回率:正确猜测正例的份额。 F1分数:准确率和召回率的谐和平均数。 混杂矩阵:展现模型猜测成果的详细情况。
6. 过拟合与欠拟合 过拟合:模型在练习数据上体现很好,但在新数据上体现差。 欠拟合:模型在练习数据上体现差,在新数据上体现也差。 正则化:经过增加赏罚项来避免过拟合。
7. 特征工程 特征挑选:从原始特征中挑选最有用的特征。 特征提取:从原始数据中提取新的特征。 特征编码:将类别特征转化为数值特征。
8. 机器学习结构 TensorFlow:由Google开发,用于深度学习的开源结构。 PyTorch:由Facebook开发,用于深度学习的开源结构。 Scikitlearn:用于机器学习的Python库,供给各种算法和东西。
9. 实践项目 数据搜集:获取用于练习和测验的数据。 数据预处理:清洗、转化和归一化数据。 模型练习:运用算法和练习数据练习模型。 模型评价:运用测验数据评价模型功能。 模型布置:将模型使用于实践场景。
10. 继续学习 在线学习:模型在接收到新数据时进行更新。 搬迁学习:运用一个已练习的模型来处理新问题。
这些笔记涵盖了机器学习的根底知识,为深化学习机器学习供给了结构。跟着技能的不断发展,机器学习范畴也在不断进步,新的算法和东西不断涌现。
机器学习根底笔记
什么是机器学习
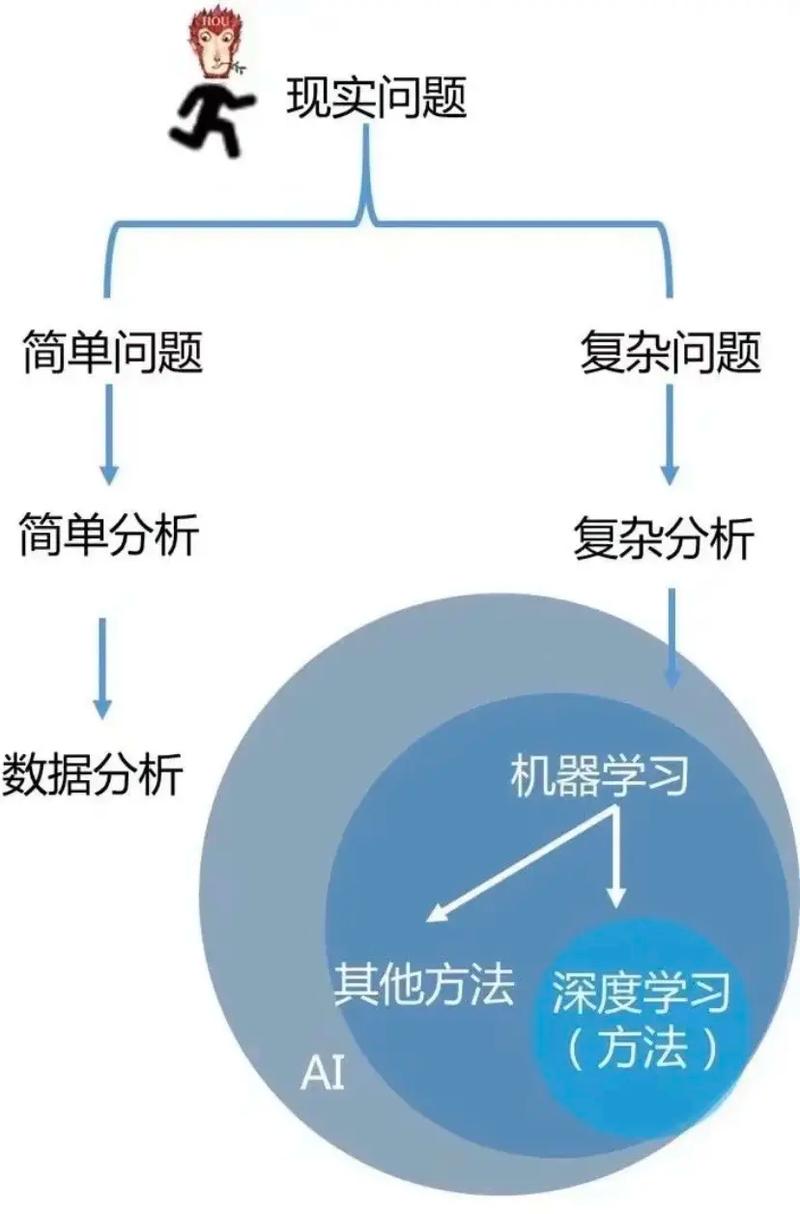
机器学习(Machine Learning)是一门研讨怎么让计算机从数据中学习并做出决议计划或猜测的学科。它归于人工智能(Artificial Intelligence, AI)的一个分支,旨在让计算机具有相似人类的智能,可以经过经历改善其功能。
机器学习的品种
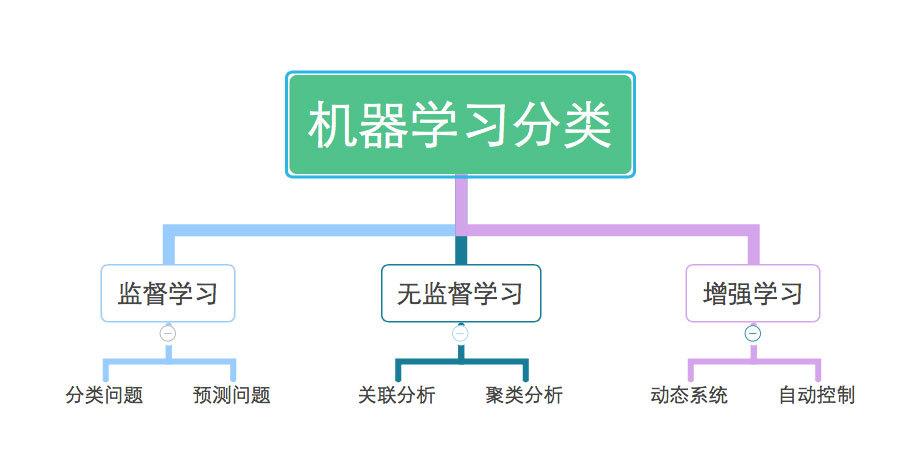
机器学习首要分为以下几品种型:
监督学习(Supervised Learning):经过已符号的练习数据来练习模型,使其可以对不知道数据进行猜测。
无监督学习(Unsupervised Learning):运用未符号的数据来发现数据中的形式和结构。
半监督学习(Semi-supervised Learning):结合了监督学习和无监督学习,运用少数符号数据和很多未符号数据来练习模型。
强化学习(Reinforcement Learning):经过奖赏和赏罚机制来辅导模型学习最优战略。
机器学习的办法

机器学习办法首要包含以下几种:
计算办法:根据概率论和计算学原理,经过剖析数据来发现规矩。
根据实例的办法:经过存储和检索实例来处理问题。
根据模型的办法:经过构建数学模型来描绘学习进程。
根据规矩的办法:经过界说规矩来辅导学习进程。
学习模型
学习模型是机器学习中的中心概念,以下是几种常见的模型:
机器学习使用

自然语言处理(Natural Language Processing, NLP):如机器翻译、情感剖析、文本分类等。
计算机视觉(Computer Vision):如图像辨认、方针检测、人脸辨认等。
引荐体系(Recommendation System):如电影引荐、产品引荐等。
医疗确诊:如疾病猜测、药物研制等。
机器学习东西和结构
Scikit-learn:一个开源的Python机器学习库,供给了多种机器学习算法和东西。
TensorFlow:由Google开发的一个开源机器学习结构,适用于构建和练习大规模机器学习模型。
Keras:一个根据TensorFlow的Python深度学习库,供给了简练的API和丰厚的预练习模型。
PaddlePaddle:由百度开发的一个开源深度学习渠道,适用于构建和练习大规模深度学习模型。
机器学习是一门充溢挑战和机会的学科,跟着技能的不断发展,机器学习将在更多范畴发挥重要作用。本文扼要介绍了机器学习的根底知识,期望对初学者有所协助。
未经允许不得转载:全栈博客园 » 机器学习根底笔记, 什么是机器学习
 机器学习实战项目引荐,从理论到实践的桥梁
机器学习实战项目引荐,从理论到实践的桥梁 ai生图软件,敞开构思无限的未来
ai生图软件,敞开构思无限的未来 吴恩达机器学习书,从入门到通晓的攻略
吴恩达机器学习书,从入门到通晓的攻略 机器学习 翻译,跨过言语障碍的智能桥梁
机器学习 翻译,跨过言语障碍的智能桥梁 AI灯谱 器件归纳,立异照明解决计划的诞生
AI灯谱 器件归纳,立异照明解决计划的诞生 ai起名,立异与功率的完美结合
ai起名,立异与功率的完美结合 ai 归纳才干速写,立异与应战并存
ai 归纳才干速写,立异与应战并存 ai软件归纳实例,智能座舱与高中数学教育视频生成
ai软件归纳实例,智能座舱与高中数学教育视频生成










