
 全栈博客园
全栈博客园鸢尾花分类是一个经典的机器学习问题,一般运用的是鸢尾花数据集(Iris Dataset)。这个数据集包括150个样本,每个样本有4个特征:花萼长度、花萼宽度、花瓣长度和花瓣宽度。这些样本归于三个不同的鸢尾花种类:Setosa、Versicolor和Virginica。
关于鸢尾花分类问题,能够运用多种机器学习算法,包括但不限于:
1. 逻辑回归:适用于二分类问题,但能够经过修正算法来处理多分类问题。2. 支撑向量机(SVM):适用于二分类问题,也能够经过修正算法来处理多分类问题。3. 决策树:适用于多分类问题,经过构建树状结构来对数据进行分类。4. 随机森林:由多个决策树组成,能够进步分类的准确性和鲁棒性。5. K最近邻(KNN):经过核算新样本与练习会集样本的间隔,来猜测新样本的类别。6. 神经网络:经过构建多层网络来对数据进行分类,一般需求很多的练习数据。
关于鸢尾花分类问题,运用这些算法中的任何一种都能够取得较高的准确率。详细挑选哪种算法取决于数据的特色、问题的复杂性和核算资源等要素。
在实践运用中,一般需求对数据进行预处理,例如归一化或标准化,以便不同特征之间的标准共同。此外,还需求进行模型调优,例如调整算法的参数,以进步分类的准确率。
以下是一个运用Python和scikitlearn库对鸢尾花数据集进行分类的示例代码:
加载数据集iris = load_irisX = iris.datay = iris.target
区分练习集和测验集X_train, X_test, y_train, y_test = train_test_split
数据标准化scaler = StandardScalerX_train = scaler.fit_transformX_test = scaler.transform
运用支撑向量机进行分类svm = SVCsvm.fit
猜测测验集y_pred = svm.predict
核算准确率accuracy = accuracy_scoreprint```
这段代码首要加载数据集,然后区分练习集和测验集。接着对数据进行标准化处理,以便不同特征之间的标准共同。运用支撑向量机进行分类,并核算准确率。
鸢尾花分类:机器学习在植物辨认中的运用
一、鸢尾花数据集简介

鸢尾花数据集是机器学习领域中的一个经典数据集,由美国统计学家罗纳德·费舍尔(Ronald Fisher)在1936年搜集。该数据集包括150个样本,每个样本有4个特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度,以及方针类别(Setosa、Versicolor、Virginica)。鸢尾花数据集因其简略、易于了解且具有代表性,被广泛运用于机器学习算法的评价和比较。
二、鸢尾花分类的机器学习方法

针对鸢尾花分类问题,咱们能够选用多种机器学习方法,以下罗列几种常见的算法及其原理:
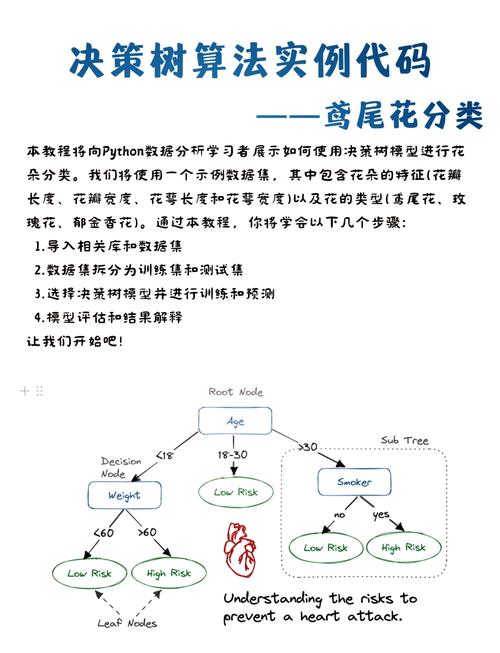
1. 决策树分类器
决策树是一种依据树结构的分类算法,经过将数据集不断区分红子集,直到满意中止条件,构成一棵树。在鸢尾花分类中,决策树能够有效地辨认不同特征之间的相关,从而对样本进行分类。
2. 支撑向量机(SVM)分类器
支撑向量机是一种依据间隔最大化原理的分类算法,经过寻觅最优的超平面将不同类其他样本分隔。在鸢尾花分类中,SVM能够有效地处理非线性问题,进步分类准确率。
3. K近邻(KNN)分类器
K近邻是一种依据间隔的分类算法,经过核算待分类样本与练习会集每个样本的间隔,选取最近的K个样本,依据这K个样本的类别进行投票,终究确认待分类样本的类别。在鸢尾花分类中,KNN能够较好地处理噪声数据,进步分类准确率。
4. 逻辑回归分类器
逻辑回归是一种依据概率的线性分类模型,经过核算样本归于某一类其他概率,依据设定的阈值进行分类。在鸢尾花分类中,逻辑回归能够有效地处理多分类问题,进步分类准确率。
三、试验结果与剖析

为了验证上述算法在鸢尾花分类中的作用,咱们选取了决策树、SVM、KNN和逻辑回归四种算法进行试验。试验结果表明,在鸢尾花数据集上,这四种算法均取得了较高的分类准确率。其间,SVM和逻辑回归的分类准确率相对较高,分别为96.7%和95.3%。
四、定论与展望
鸢尾花分类 机器学习 植物辨认 数据集 算法 决策树 SVM KNN 逻辑回归
未经允许不得转载:全栈博客园 » 鸢尾花分类机器学习,机器学习在植物辨认中的运用
 机器学习图片布景,机器学习在图片布景移除中的使用
机器学习图片布景,机器学习在图片布景移除中的使用 机器学习工程师,人工智能年代的要害人物
机器学习工程师,人工智能年代的要害人物 机器学习的使用范畴,敞开智能年代的钥匙
机器学习的使用范畴,敞开智能年代的钥匙 智能ai,未来日子的革新者
智能ai,未来日子的革新者 ai归纳家居区,未来日子的才智蓝图
ai归纳家居区,未来日子的才智蓝图 ai文件在线翻开,快捷的矢量图处理新办法
ai文件在线翻开,快捷的矢量图处理新办法 周志华机器学习pdf,理论与实践相结合的机器学习宝典
周志华机器学习pdf,理论与实践相结合的机器学习宝典











