
 全栈博客园
全栈博客园3. 测验集(Test Set):测验集是用于评价模型功能的数据集,它独立于练习集,用于验证模型在实践运用中的体现。
4. 特征(Feature):特征是数据会集的特点或变量,它们用于构建机器学习模型。
7. 无监督学习(Unsupervised Learning):无监督学习是一种机器学习办法,它运用未符号的数据集来发现数据中的形式和结构。
8. 强化学习(Reinforcement Learning):强化学习是一种机器学习办法,它经过与环境交互来学习最佳战略。
9. 分类(Classification):分类是一种监督学习使命,它将数据分为不同的类别。
10. 回归(Regression):回归是一种监督学习使命,它猜测接连数值的输出。
11. 过拟合(Overfitting):过拟合是指模型在练习数据上体现杰出,但在测验数据上体现欠安的现象。
12. 欠拟合(Underfitting):欠拟合是指模型在练习数据上体现欠安,无法捕捉数据中的杂乱形式。
13. 差错方差权衡(BiasVariance Tradeoff):差错方差权衡是机器学习中一个重要的概念,它描绘了模型杂乱度与泛化才能之间的联系。
14. 穿插验证(CrossValidation):穿插验证是一种评价模型功能的办法,它将数据集分红多个子集,并运用不同的子集进行练习和测验。
15. 梯度下降(Gradient Descent):梯度下降是一种优化算法,它用于最小化机器学习模型的丢失函数。
16. 支撑向量机(Support Vector Machine, SVM):支撑向量机是一种监督学习算法,它用于分类和回归使命。
17. 决议计划树(Decision Tree):决议计划树是一种监督学习算法,它经过一系列规矩来对数据进行分类。
18. 随机森林(Random Forest):随机森林是一种集成学习办法,它结合多个决议计划树来进步模型的泛化才能。
19. 神经网络(Neural Network):神经网络是一种模仿人脑神经元结构的核算模型,它由多个层次和节点组成。
20. 深度学习(Deep Learning):深度学习是一种神经网络技能,它运用多层网络结构来学习数据中的杂乱形式。
21. 激活函数(Activation Function):激活函数是神经网络中用于引进非线性性的函数。
22. 丢失函数(Loss Function):丢失函数是用于评价模型猜测与实践值之间差异的函数。
23. 正则化(Regularization):正则化是一种避免模型过拟合的技能,它经过增加赏罚项来约束模型的杂乱度。
24. 数据预处理(Data Preprocessing):数据预处理是指对原始数据进行清洗、转化和归一化等操作,以进步模型的学习效果。
25. 特征工程(Feature Engineering):特征工程是指从原始数据中提取或结构新的特征,以进步模型的学习效果。
26. 超参数(Hyperparameter):超参数是机器学习模型中的参数,它们在练习进程中需求手动设置。
27. 集成学习(Ensemble Learning):集成学习是一种结合多个模型来进步猜测功能的办法。
28. 搬迁学习(Transfer Learning):搬迁学习是一种运用已练习模型的常识来进步新使命学习效果的办法。
29. 半监督学习(SemiSupervised Learning):半监督学习是一种机器学习办法,它运用少数符号数据和很多未符号数据来练习模型。
30. 在线学习(Online Learning):在线学习是一种机器学习办法,它运用新数据来更新模型,而无需从头练习整个模型。
31. 聚类(Clustering):聚类是一种无监督学习使命,它将数据分为不同的簇。
32. 相关规矩学习(Association Rule Learning):相关规矩学习是一种无监督学习使命,它发现数据中频频呈现的项集和相关规矩。
33. 反常检测(Anomaly Detection):反常检测是一种无监督学习使命,它辨认数据中的反常或离群点。
34. 降维(Dimensionality Reduction):降维是一种技能,它经过削减特征的数量来简化数据集。
35. 自然言语处理(Natural Language Processing, NLP):自然言语处理是人工智能的一个分支,它重视于核算机和人类言语之间的交互。
36. 核算机视觉(Computer Vision):核算机视觉是人工智能的一个分支,它重视于核算机怎么了解和解说视觉信息。
37. 强化学习环境(Reinforcement Learning Environment):强化学习环境是强化学习模型与之交互的环境,它供给状况、奖赏和举动空间。
38. 马尔可夫决议计划进程(Markov Decision Process, MDP):马尔可夫决议计划进程是一种数学结构,它描绘了强化学习中的状况、动作、奖赏和搬运概率。
39. Q学习(QLearning):Q学习是一种强化学习算法,它经过学习Q值函数来找到最优战略。
40. 战略梯度(Policy Gradient):战略梯度是一种强化学习算法,它直接优化战略函数来进步功能。
41. 深度Q网络(Deep QNetwork, DQN):深度Q网络是一种结合深度学习和Q学习的强化学习算法。
42. 生成对立网络(Generative Adversarial Network, GAN):生成对立网络是一种深度学习模型,它由生成器和判别器组成,用于生成传神的数据。
43. 变分自编码器(Variational Autoencoder, VAE):变分自编码器是一种深度学习模型,它用于生成新的数据或对数据进行编码。
44. 自监督学习(SelfSupervised Learning):自监督学习是一种无监督学习使命,它经过猜测数据中的躲藏部分来学习表明。
45. 元学习(MetaLearning):元学习是一种机器学习办法,它学习怎么学习,以进步模型在新使命上的泛化才能。
这些术语涵盖了机器学习中的许多基本概念和算法,了解它们有助于更好地了解和运用机器学习技能。
机器学习术语解析
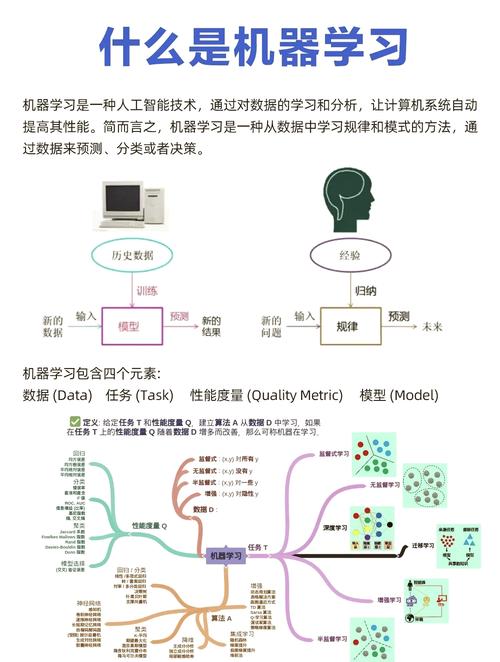
1. 机器学习(Machine Learning,ML)
机器学习是人工智能的一个分支,它使核算机体系可以从数据中学习并做出决议计划或猜测,而不是经过清晰的编程指令。机器学习模型经过剖析数据,自动辨认数据中的形式,并运用这些形式进行猜测或决议计划。
2. 监督学习(Supervised Learning)

3. 无监督学习(Unsupervised Learning)
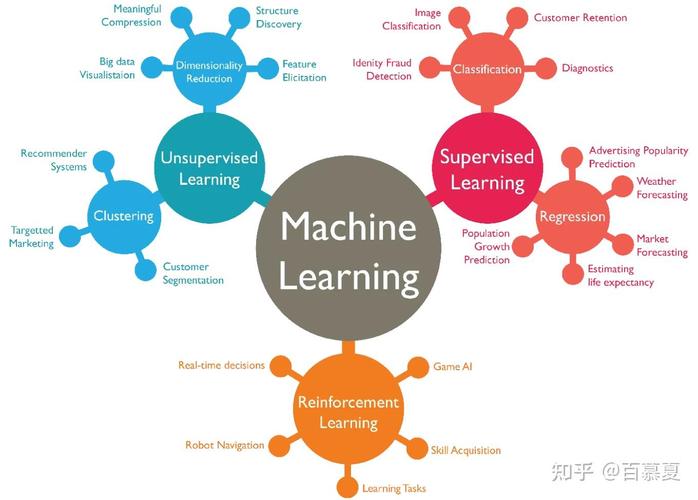
4. 强化学习(Reinforcement Learning)

强化学习是一种机器学习办法,其间模型经过与环境的交互来学习。模型经过测验不同的动作并接纳奖赏或赏罚来学习最佳战略。强化学习在游戏、机器人操控和引荐体系等范畴有广泛运用。
5. 特征(Feature)
特征是描绘数据样本的特点或变量。在机器学习中,特征用于表明输入数据,以便模型可以从中学习。特征提取和挑选是机器学习进程中的重要过程,有助于进步模型的功能。
模型是机器学习算法的输出,它表明了数据中的形式和联系。模型可以是简略的线性回归方程,也可以是杂乱的神经网络。模型的挑选和调优关于进步猜测精确性至关重要。
7. 丢失函数(Loss Function)

丢失函数是衡量模型猜测差错的目标。在练习进程中,丢失函数用于评价模型猜测与实践值之间的差异,并辅导模型优化。常见的丢失函数包含均方差错(MSE)和穿插熵丢失。
8. 优化算法(Optimization Algorithm)
优化算法用于最小化丢失函数,然后进步模型的功能。常见的优化算法包含梯度下降、随机梯度下降和Adam优化器。优化算法的挑选和参数设置对模型的收敛速度和功能有重要影响。
9. 过拟合(Overfitting)
过拟合是指模型在练习数据上体现杰出,但在未见过的数据上体现欠安。过拟合一般发生在模型过于杂乱,可以捕捉到练习数据中的噪声和细节,而不是真实的数据形式。
10. 欠拟合(Underfitting)

欠拟合是指模型在练习数据上体现欠安,由于它过于简略,无法捕捉到数据中的杂乱形式。欠拟合一般发生在模型过于简略,无法学习到满足的信息来做出精确的猜测。
11. 精确率(Accuracy)

精确率是衡量分类模型功能的目标,表明模型正确猜测的样本份额。精确率越高,模型在分类使命上的体现越好。
12. 召回率(Recall)
召回率是衡量分类模型功能的目标,表明模型正确辨认为正类的样本份额。召回率越高,模型在辨认正类样本方面的体现越好。
13. F1 值(F1 Score)
F1 值是精确率和召回率的谐和平均值,用于衡量分类模型的归纳功能。F1 值越高,模型在分类使命上的体现越好。
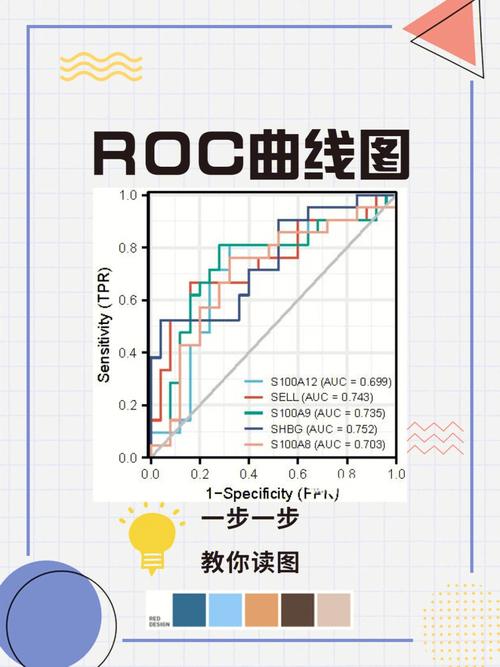
14. ROC 曲线(Receiver Operating Characteristic Curve)
ROC 曲线是用于评价分类模型功能的曲线,它展现了不同阈值下模型的真阳性率(TPR)与假阳性率(FPR)之间的联系。ROC 曲线的下方面积(AUC)是衡量模型功能的目标,AUC 越高,模型功能越好。
经过以上对机器学习术语的解析,信任咱们对机器学习的基本概念和常用术语有了更深化的了解。在学习和运用机器学习的进程中,把握这些术语将有助于进步咱们的专业素质和实践操作才能。
未经允许不得转载:全栈博客园 » 机器学习术语,机器学习术语解析
 ai生成图片软件免费,构思无限,轻松上手
ai生成图片软件免费,构思无限,轻松上手 人工ai,未来日子的革新者
人工ai,未来日子的革新者 AI编程,未来技能浪潮中的编程新篇章
AI编程,未来技能浪潮中的编程新篇章 ai归纳帮手app,AI归纳帮手APP——智能日子新同伴
ai归纳帮手app,AI归纳帮手APP——智能日子新同伴 ai阅读器,互联网年代的改造者
ai阅读器,互联网年代的改造者 ai算法,驱动未来智能化的中心力气
ai算法,驱动未来智能化的中心力气 好记星学习机器人,智能教育的新同伴
好记星学习机器人,智能教育的新同伴 我国归纳AI换脸,我国AI换脸技能开展与运用现状
我国归纳AI换脸,我国AI换脸技能开展与运用现状










