
 全栈博客园
全栈博客园本地向量数据库是一种用于存储和办理高维向量的数据库体系。它答使用户快速查询和检索与给定查询向量类似的其他向量。本地向量数据库一般用于机器学习、图画辨认、自然语言处理等范畴,其间需求处理很多的高维数据。
以下是本地向量数据库的一些常见特色和用处:
1. 高效的存储:本地向量数据库规划用于高效地存储高维向量数据。它们一般运用紧缩技能来削减存储空间,一起坚持数据的质量和精确性。
2. 快速查询:本地向量数据库供给快速查询功用,答使用户快速找到与给定查询向量类似的其他向量。这一般经过运用索引结构,如kd树、球树或部分灵敏哈希(LSH)来完成。
3. 可扩展性:本地向量数据库规划为可扩展,以习惯很多数据和高并发查询的需求。它们一般支撑分布式存储和核算,以完成水平扩展。
4. 多样性:本地向量数据库支撑多种数据类型,包含浮点数、整数、二进制等。它们还支撑多种查询语言和接口,以习惯不同的使用场景。
5. 使用范畴:本地向量数据库在多个范畴都有广泛的使用,包含图画辨认、语音辨认、自然语言处理、引荐体系等。它们能够协助这些范畴的使用更快速、精确地处理很多高维数据。
总归,本地向量数据库是一种专门用于存储和办理高维向量数据的数据库体系。它们具有高效的存储、快速查询、可扩展性、多样性和广泛的使用范畴等特色,为机器学习和数据发掘等范畴的使用供给了强壮的支撑。
深化解析本地向量数据库:高效数据检索与类似度查找的利器

跟着大数据年代的到来,数据量呈爆破式增加,怎么高效地进行数据检索和类似度查找成为了关键问题。本地向量数据库作为一种新式的数据存储和检索技能,凭仗其高效、灵敏的特色,在很多使用场景中展现出巨大的潜力。本文将深化解析本地向量数据库的原理、使用场景以及优势。
一、什么是本地向量数据库?
本地向量数据库是一种专门用于存储和检索高维向量数据的数据库。它经过将数据转换为向量方式,使用向量空间模型进行类似度查找,然后完成快速、精确的数据检索。与传统的依据键值对或联系型的数据库比较,向量数据库在处理高维数据、类似度查找等方面具有明显优势。
二、本地向量数据库的作业原理
本地向量数据库的作业原理首要包含以下几个过程:
数据预处理:将原始数据转换为向量方式,一般选用词嵌入、图画特征提取等办法。
向量存储:将向量数据存储在数据库中,一般选用稀少矩阵或紧缩感知等技能进行存储,以下降存储空间。
索引构建:依据向量数据的特色,构建相应的索引结构,如球树、k-d树等,以加快类似度查找。
类似度查找:依据用户查询,在数据库中检索与查询向量最类似的向量,回来查找成果。
三、本地向量数据库的使用场景
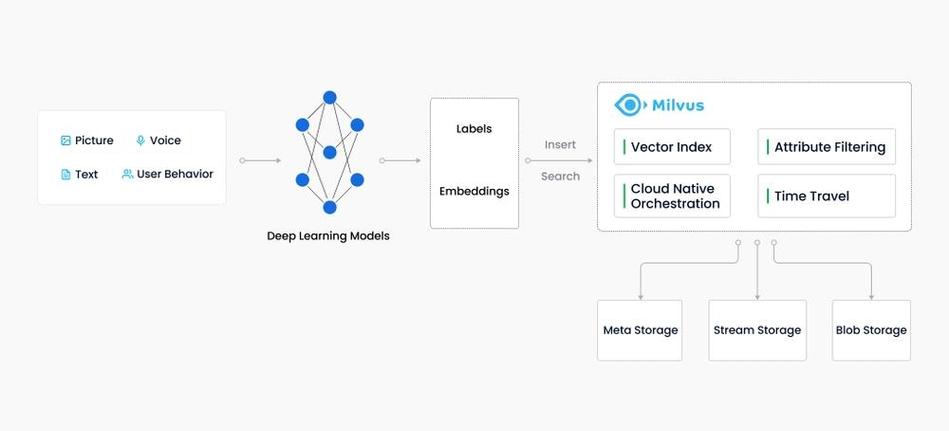
本地向量数据库在很多使用场景中具有广泛的使用价值,以下罗列几个典型场景:
图画查找:经过将图画转换为向量,完成快速、精确的图画检索。
引荐体系:使用向量数据库对用户行为数据进行类似度查找,为用户供给个性化的引荐。
自然语言处理:将文本数据转换为向量,完成文本类似度查找、聚类等使命。
生物信息学:对基因、蛋白质等生物数据进行类似度查找,加快科学研究。
四、本地向量数据库的优势
与传统的数据库比较,本地向量数据库具有以下优势:
高效性:向量数据库选用向量空间模型进行类似度查找,具有极高的检索速度。
灵敏性:支撑多种向量类型和索引结构,适用于不同场景下的数据检索需求。
可扩展性:向量数据库支撑分布式存储和核算,可轻松应对海量数据。
易用性:供给丰厚的API和东西,便利用户进行数据存储、检索和剖析。
五、本地向量数据库的开展趋势
多模态数据支撑:向量数据库将支撑更多模态的数据,如音频、视频等。
智能化:结合人工智能技能,完成更智能的数据检索和剖析。
云原生:向量数据库将更好地习惯云核算环境,完成弹性扩展和高效运维。
本地向量数据库作为一种高效、灵敏的数据存储和检索技能,在很多使用场景中展现出巨大的潜力。跟着技能的不断开展,向量数据库将在未来发挥愈加重要的效果,助力企业完成数据驱动决议计划,推进人工智能、大数据等范畴的立异与开展。
未经允许不得转载:全栈博客园 » 本地向量数据库,高效数据检索与类似度查找的利器
 mac卸载mysql,Mac体系下MySQL数据库的完全卸载攻略
mac卸载mysql,Mac体系下MySQL数据库的完全卸载攻略 城市大数据剖析,助力才智城市建造
城市大数据剖析,助力才智城市建造 pubmed数据库官网,深化探究PubMed数据库官网——生物医学文献检索的宝库
pubmed数据库官网,深化探究PubMed数据库官网——生物医学文献检索的宝库 数据库开展趋势,立异与革新并行
数据库开展趋势,立异与革新并行 jsp数据库衔接
jsp数据库衔接 大数据新技能,大数据新技能的兴起与应战
大数据新技能,大数据新技能的兴起与应战 大数据专业学什么,大数据专业概述
大数据专业学什么,大数据专业概述 大数据和区块链,交融立异,构建未来金融生态
大数据和区块链,交融立异,构建未来金融生态









