
 全栈博客园
全栈博客园在R言语中,去重一般运用`unique`函数或许`duplicated`函数。以下是这两种办法的扼要介绍:
1. `unique`函数:回来数据框、矩阵或向量的仅有值。假如数据框中有重复的行,`unique`函数将回来不重复的行。
2. `duplicated`函数:回来一个逻辑向量,表明数据框、矩阵或向量中的哪些行或元素是重复的。
下面是一个简略的比如,展现怎么运用这两种办法去重:
```R 创立一个数据框df 运用unique函数去重unique_df 运用duplicated函数去重 首要,找出重复的行duplicated_rows 显现成果unique_dfdf_without_duplicates```
在这个比如中,`unique_df`将只包含不重复的行,而`df_without_duplicates`也将只包含不重复的行。`duplicated`函数回来的逻辑向量`duplicated_rows`能够用来挑选或扫除重复的行。
R言语数据去重:高效处理重复数据的技巧
在数据剖析过程中,数据去重是一个常见且重要的过程。重复数据不只会占用不必要的存储空间,还或许影响剖析成果的准确性。本文将具体介绍R言语中处理数据去重的几种办法,帮助您高效地整理数据。
一、数据去重的重要性

数据去重是数据预处理的关键过程之一。重复数据或许会导致以下问题:
添加数据集的体积,影响存储和核算功率。
导致计算成果的误差,影响剖析成果的准确性。
在数据可视化时,重复数据或许会误导观察者。
二、R言语数据去重办法

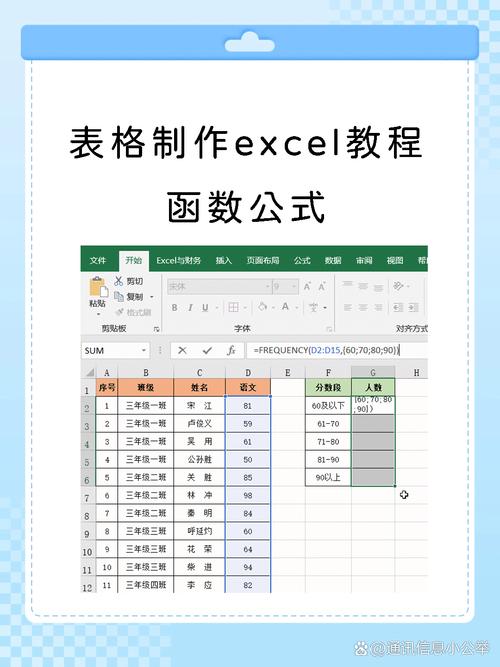
1. 运用unique函数

unique函数是R言语中处理数据去重的根底函数。它能够去除向量、矩阵或数据框中的重复元素。
unique(data_frame)
例如,以下代码将去除数据框df中的重复行:
2. 运用duplicated函数
duplicated函数用于检测数据框中的重复行。它回来一个逻辑向量,指示每行是否为重复行。
duplicated(data_frame)
以下代码将去除数据框df中重复的行:
df_unique
3. 运用dplyr包中的distinct函数
dplyr包是R言语中一个强壮的数据处理东西。distinct函数能够去除数据框中的重复行,并保存初次呈现的行。
library(dplyr)
distinct(data_frame)
以下代码将去除数据框df中重复的行:
df_unique %
distinct()
4. 运用data.table包中的unique函数
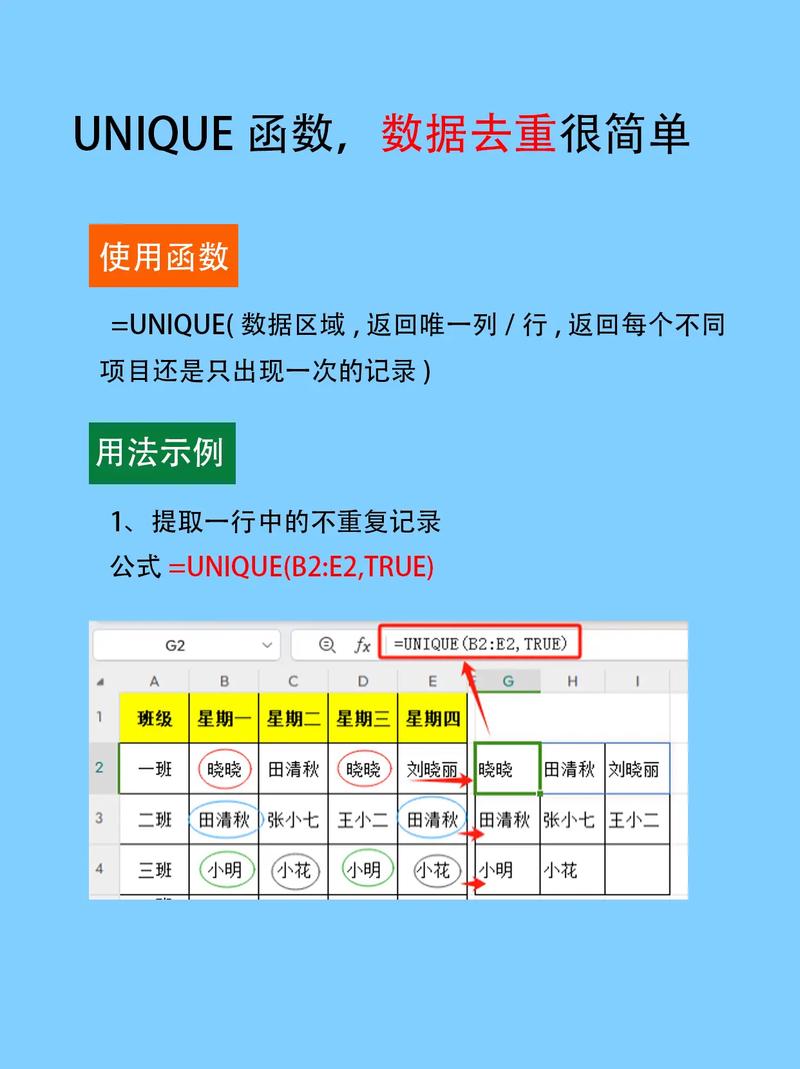
data.table包是R言语中一个高性能的数据处理东西。它的unique函数能够高效地去除数据框中的重复行。
library(data.table)
unique(data_frame)
以下代码将去除数据框df中重复的行:
df_unique
数据去重是数据剖析过程中的重要过程。在R言语中,有多种办法能够完成数据去重,包含unique函数、duplicated函数、dplyr包中的distinct函数以及data.table包中的unique函数。依据实践需求挑选适宜的办法,能够帮助您高效地整理数据,进步剖析成果的准确性。
未经允许不得转载:全栈博客园 » r言语去重,高效处理重复数据的技巧
 ruby-china,Ruby China 社区展开现状与未来展望
ruby-china,Ruby China 社区展开现状与未来展望 java插件,进步开发功率的利器
java插件,进步开发功率的利器 JAVA调集结构,Java调集结构概述
JAVA调集结构,Java调集结构概述 用c言语编写的程序被称为,探究其魅力与价值
用c言语编写的程序被称为,探究其魅力与价值 米可GO,米可智能ai配音官网
米可GO,米可智能ai配音官网 swift是什么付款方法,什么是SWIFT付款?
swift是什么付款方法,什么是SWIFT付款? ruby脚本,自动化使命,进步功率
ruby脚本,自动化使命,进步功率










