
 全栈博客园
全栈博客园散布式数据库是一个数据库体系,它将数据存储在多个物理方位上,这些方位能够散布在不同的服务器、不同的地理方位乃至不同的网络上。散布式数据库的首要意图是进步数据处理的功率、可靠性和可扩展性。
以下是散布式数据库的一些要害特色:
1. 数据散布:数据散布在多个节点上,每个节点或许存储数据库的一部分数据。这些节点能够是物理服务器、虚拟机或云实例。
2. 数据一致性:散布式数据库需求保证数据在不同节点上的一致性。这一般经过仿制、分区和同步机制来完成。
3. 透明性:用户和使用程序应该能够像拜访单个数据库相同拜访散布式数据库,而不需求知道数据的物理方位。
4. 容错性:因为数据散布在多个节点上,即便某些节点发生毛病,体系依然能够持续运转。
5. 可扩展性:散布式数据库能够经过添加更多的节点来轻松扩展,以处理更多的数据或更高的负载。
6. 高功能:经过并行处理和负载均衡,散布式数据库能够供给比单节点数据库更高的功能。
7. 杂乱性:散布式数据库的规划和办理一般比单节点数据库更杂乱,因为需求处理数据散布、一致性和毛病搬运等问题。
8. 通讯开支:因为数据散布在多个节点上,节点之间的通讯或许会发生额定的开支。
9. 业务处理:散布式数据库需求支撑散布式业务,保证业务的原子性、一致性、阻隔性和持久性(ACID特色)。
10. 安全性:散布式数据库需求保证数据在传输和存储过程中的安全性,避免数据走漏和未经授权的拜访。
散布式数据库在许多场景中都有使用,例如大型企业、金融机构、在线服务供给商和科学核算等,它们需求处理很多的数据并供给高可用性和高功能。
什么是散布式数据库?
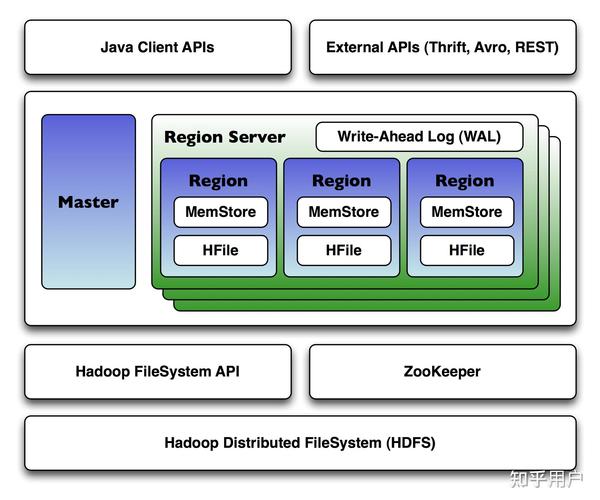
散布式数据库(Distributed Database)是一种数据库技能,它将数据存储在多个物理方位的核算机上,这些核算机经过网络连接在一起,构成一个逻辑上一致的数据库体系。这种规划旨在进步体系的可扩展性、可用性和功能,以满意大规模数据存储和处理的应战。
散布式数据库的基本概念
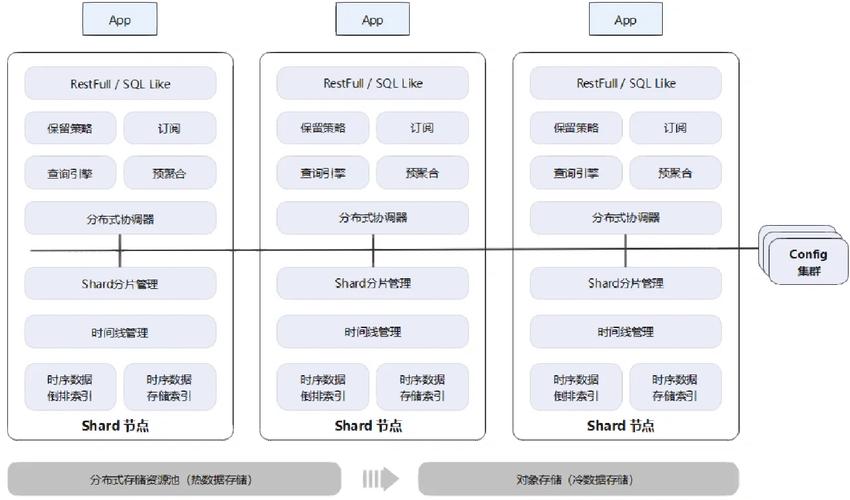
散布式数据库的中心概念是将数据涣散存储在多个节点上,这些节点能够是物理服务器或虚拟机。每个节点都担任存储一部分数据,而且能够独立地处理查询和业务。虽然数据散布在不同的物理方位,但用户和使用程序依然能够像操作单一数据库相同拜访这些数据。
散布式数据库的组件
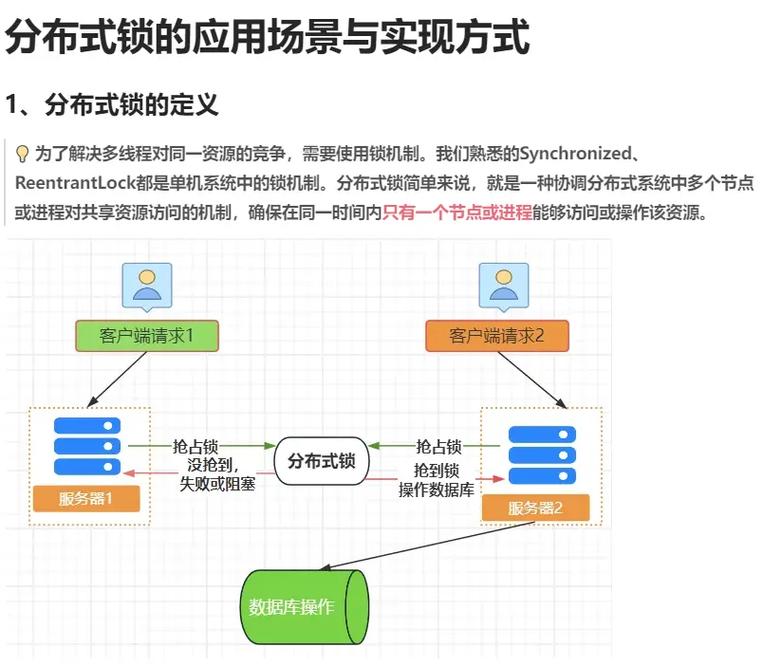
散布式数据库体系一般包括以下组件:
节点(Node):散布式数据库中的每个物理或虚拟核算机。
分区(Partition):数据在多个节点之间的区分方法,能够是水平分区或笔直分区。
副本(Replica):数据的多个副本,用于进步可用性和容错性。
和谐者(Coordinator):担任办理和和谐散布式业务的节点。
散布式数据库的特色
散布式数据库具有以下特色:
高可扩展性:经过添加更多的节点,能够水平扩展体系的处理才能和存储容量。
高可用性:经过数据仿制和毛病康复机制,保证数据的高可用性和体系的接连运转。
高功能:多个节点能够并行处理查询和业务,进步体系的全体功能。
数据透明性:用户和使用程序无需关怀数据的物理散布,能够像操作单一数据库相同拜访数据。
散布式数据库的使用场景
散布式数据库适用于以下场景:
大规模数据存储:处理海量数据,如电子商务、交际媒体、物联网等。
高可用性需求:保证体系在节点毛病的情况下依然可用。
高功能需求:进步查询和业务处理的功率。
地理散布的数据:处理跨地域的数据存储和拜访。
散布式数据库的应战
虽然散布式数据库具有许多长处,但也面对一些应战:
数据一致性问题:保证一切节点上的数据保持一致,或许需求杂乱的仿制和同步机制。
散布式业务办理:处理跨多个节点的杂乱业务,需求保证业务的原子性、一致性、阻隔性和持久性。
网络推迟和毛病:网络推迟和节点毛病或许导致功能下降和体系不可用。
办理和保护:散布式数据库的办理和保护比单一数据库更为杂乱。
散布式数据库是一种强壮的数据库技能,它经过将数据涣散存储在多个节点上,进步了体系的可扩展性、可用性和功能。虽然存在一些应战,但散布式数据库在处理大规模数据、高可用性和高功能需求方面具有明显优势。跟着技能的不断发展,散布式数据库将持续在各个领域发挥重要作用。
未经允许不得转载:全栈博客园 » 什么是散布式数据库,什么是散布式数据库?
 mysql监控,MySQL监控的重要性
mysql监控,MySQL监控的重要性 云数据库redis,高效、安全、快捷的数据存储解决方案
云数据库redis,高效、安全、快捷的数据存储解决方案 oracle装备文件途径,Oracle装备文件途径详解
oracle装备文件途径,Oracle装备文件途径详解 oracle表空间主动扩展,优化数据库功用的要害战略
oracle表空间主动扩展,优化数据库功用的要害战略 数据库域,数据库域概述
数据库域,数据库域概述 大数据剖析网站,助力企业洞悉商场脉息,驱动决议计划立异
大数据剖析网站,助力企业洞悉商场脉息,驱动决议计划立异 怎么衔接mysql数据库,怎么衔接MySQL数据库
怎么衔接mysql数据库,怎么衔接MySQL数据库











