
 全栈博客园
全栈博客园1. Hadoop:Hadoop 是一个开源结构,用于存储和处理大规模数据集。它由 HDFS(Hadoop Distributed File System)和 MapReduce 两个首要组件组成。
2. Spark:Spark 是一个快速、通用的大数据处理引擎。它支撑多种编程言语,包含 Scala、Java、Python 和 R,而且能够与 Hadoop 集成。
3. Tableau:Tableau 是一个商业智能东西,用于数据可视化和剖析。它答运用户创立交互式仪表板和陈述,以便更好地舆解数据。
4. Excel:尽管 Excel 不是一个专门的大数据剖析东西,但它仍然是一个十分盛行的数据剖析东西,特别是关于小型数据集。
5. R:R 是一个核算核算和图形的言语和环境。它广泛用于数据剖析和核算建模。
6. Python:Python 是一种广泛运用的编程言语,具有丰厚的数据剖析库,如 Pandas、NumPy 和 Matplotlib。
7. Power BI:Power BI 是微软的一个商业智能东西,用于数据可视化、陈述和剖析。它支撑多种数据源,包含 Excel、SQL Server 和云数据源。
8. SAS:SAS 是一个核算剖析和数据管理软件,广泛用于数据发掘、猜测剖析和商业智能。
9. MATLAB:MATLAB 是一个用于数值核算、数据剖析和可视化的高档编程言语和核算环境。
10. RapidMiner:RapidMiner 是一个数据科学渠道,用于数据发掘、机器学习和文本发掘。
这些东西能够根据您的详细需求和技术水平挑选运用。假如您是初学者,或许需求从简略的东西(如 Excel)开端,然后逐步过渡到更杂乱的大数据剖析东西(如 Hadoop 和 Spark)。
大数据剖析东西:助力企业发掘数据价值
跟着信息技术的飞速发展,大数据已经成为企业竞赛的重要资源。怎么有效地进行大数据剖析,发掘数据中的价值,成为企业重视的焦点。本文将介绍几种常见的大数据剖析东西,协助读者了解它们的特色和运用场景。
一、Elasticsearch:全文查找与数据剖析利器
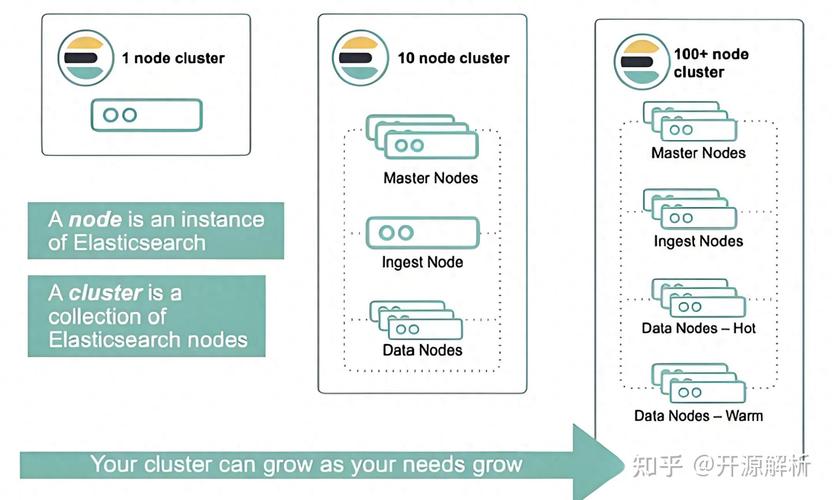
Elasticsearch是一个根据Lucene库构建的分布式、开源查找引擎,它不只拿手快速的全文查找,还具有强壮的数据存储和剖析才能。在大数据剖析范畴,Elasticsearch能够用于数据探究和预处理,协助数据科学家发现数据中的潜在形式、异常值以及数据之间的相关联系。
特色:
高效处理大规模数据
支撑全文查找和数据剖析
易于扩展和集成
运用场景:
日志剖析
查找引擎
实时监控
二、Apache Spark:快速、通用、可扩展的大数据处理结构
Apache Spark是一个开源的大数据处理结构,它供给了快速、通用、可扩展的数据处理才能。Spark能够处理大规模数据集,而且在内存中进行数据操作,然后完成高速的数据处理和剖析。
中心概念:
弹性分布式数据集(RDD):可并行操作的不行变数据调集
转化操作:如map、filter、reduce等
举动操作:如count、collect、save等
运用场景:
数据清洗、转化和数据处理
机器学习、图处理和流处理
三、Apache Hive:根据Hadoop的数据仓库东西
Apache Hive是一个根据Hadoop的数据仓库东西,用于数据存储、查询和剖析,特别合适处理大规模的数据集。它供给了一种类似于SQL的查询言语(HiveQL),能够将结构化数据存储到Hadoop HDFS上,并经过MapReduce、Tez或许Spark来进行查询剖析。
特色:
支撑SQL查询言语
易于运用和扩展
与Hadoop生态系统兼容
运用场景:
数据仓库建造
ETL使命
大数据剖析
四、Spark SQL Toolkit:轻松解析和查询数据

Spark SQL Toolkit供给了一种现代的方法来与Spark SQL进行交互,类似于SQL数据库署理。它不只能够处理惯例查询,还能在需求时进行过错康复。这关于任何处理大规模数据并期望进步功率的开发者都是极为有用的。
特色:
简化Spark SQL交互
自动化和优化查询
过错康复
运用场景:
数据加载与展现
查询和过错康复
大数据剖析东西在协助企业发掘数据价值方面发挥着重要作用。本文介绍了Elasticsearch、Apache Spark、Apache Hive和Spark SQL Toolkit等几种常见的大数据剖析东西,期望对读者有所协助。
未经允许不得转载:全栈博客园 » 大数据剖析的东西,助力企业发掘数据价值
 数据库不等于怎样写, 什么是“不等于”查询
数据库不等于怎样写, 什么是“不等于”查询 mysql8.0
mysql8.0 mysql数据库备份办法,MySQL数据库备份办法详解
mysql数据库备份办法,MySQL数据库备份办法详解 网贷大数据怎样查,了解你的网贷信誉情况
网贷大数据怎样查,了解你的网贷信誉情况 大数据事务的根底,大数据事务概述
大数据事务的根底,大数据事务概述 重装mysql,预备作业
重装mysql,预备作业 神策大数据,引领企业数字化转型的新引擎
神策大数据,引领企业数字化转型的新引擎













