
 全栈博客园
全栈博客园机器学习练习是一个触及多个进程和技巧的进程,下面我将为您具体介绍一些机器学习练习的秘籍,协助您更好地把握机器学习。
1. 数据预处理:在开端练习之前,保证您的数据集是洁净的、格局正确的,而且没有缺失值。数据预处理包含数据清洗、特征工程、数据标准化等进程。
2. 挑选适宜的模型:依据您的使命类型(如分类、回归、聚类等)和数据集的特色,挑选一个适宜的机器学习模型。常见的模型有线性回归、决策树、支撑向量机、神经网络等。
3. 调整超参数:超参数是机器学习模型的一部分,它们对模型的功能有重要影响。经过调整超参数,能够优化模型的功能。常见的超参数包含学习率、正则化项、树的数量等。
4. 穿插验证:穿插验证是一种评价模型功能的办法,它能够避免模型过拟合。在穿插验证中,数据集被分为多个子集,每个子集都被用作练习集和验证集。
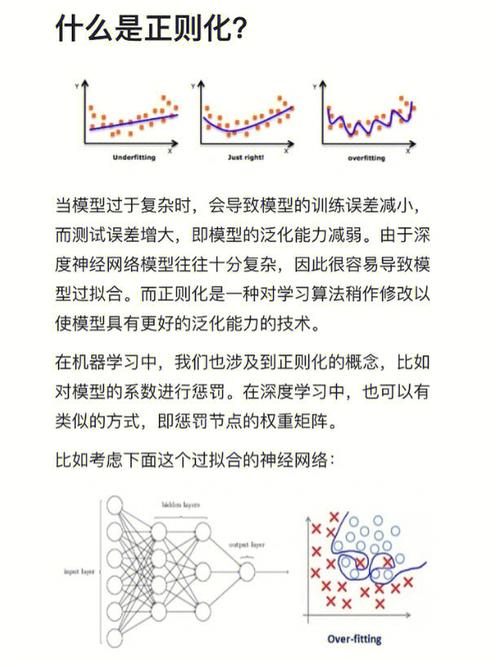
5. 正则化:正则化是一种避免模型过拟合的技能。常见的正则化办法包含L1正则化、L2正则化和dropout。
6. 学习率调整:学习率是决议模型收敛速度的重要参数。经过调整学习率,能够优化模型的功能。常见的调整办法包含学习率衰减和自适应学习率。
7. 数据增强:数据增强是一种经过改动原始数据来添加数据集多样性的办法。它能够协助模型更好地泛化,进步模型的功能。
8. 模型集成:模型集成是一种经过组合多个模型来进步模型功能的办法。常见的集成办法包含Bagging、Boosting和Stacking。
9. 模型评价:在练习完成后,需求对模型进行评价。常见的评价目标包含精确率、召回率、F1分数、均方差错等。
10. 模型布置:将练习好的模型布置到实践运用中,以便在实践环境中运用。布置进程中需求考虑模型的实时性、可扩展性和可维护性。
机器学习练习秘籍:高效进步模型功能的有用攻略
一、挑选适宜的机器学习算法
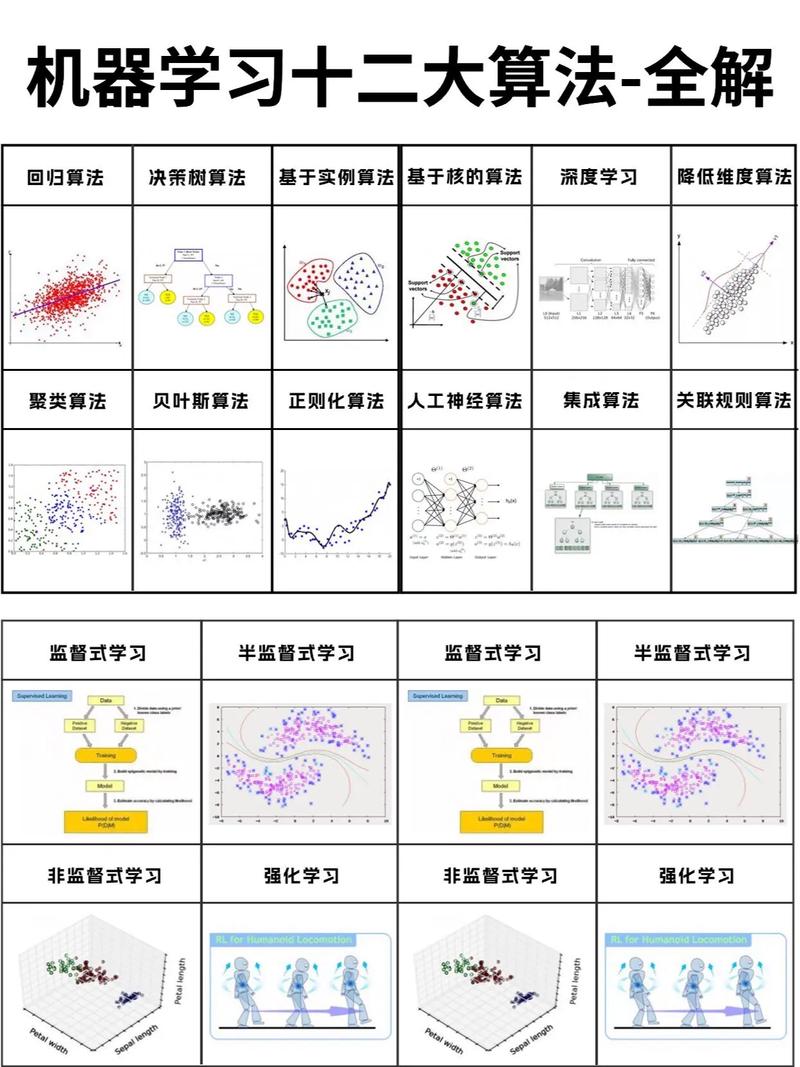
线性回归:适用于线性联系较强的数据,如房价猜测、股票价格猜测等。
逻辑回归:适用于二分类问题,如邮件分类、垃圾邮件检测等。
支撑向量机(SVM):适用于非线性联系较强的数据,如人脸辨认、文本分类等。
决策树:适用于分类和回归问题,具有较好的可解释性。
随机森林:依据决策树的集成学习办法,适用于处理大规模数据。
神经网络:适用于杂乱非线性联系的数据,如图像辨认、语音辨认等。
二、数据预处理与特征工程

数据清洗:去除缺失值、异常值等不完整或不精确的数据。
数据标准化:将不同量纲的数据转换为同一量纲,便于模型练习。
特征提取:从原始数据中提取出对模型练习有协助的特征。
特征挑选:从提取出的特征中挑选对模型练习最有协助的特征。
三、模型练习与调优
挑选适宜的练习集和测验集:保证练习集和测验集具有代表性,避免过拟合。
调整模型参数:经过穿插验证等办法,找到最优的模型参数。
运用正则化技能:避免模型过拟合,进步泛化才能。
集成学习办法:将多个模型组合起来,进步猜测功能。
四、模型评价与优化
挑选适宜的评价目标:如精确率、召回率、F1值等。
剖析模型差错:找出模型猜测过错的原因,并进行优化。
调整模型结构:依据实践情况,对模型结构进行调整。
继续练习:跟着新数据的堆集,对模型进行继续练习,进步模型功能。
本文介绍了机器学习练习的秘籍,包含挑选适宜的算法、数据预处理与特征工程、模型练习与调优、模型评价与优化等方面。期望这些技巧能协助您在机器学习范畴获得更好的效果。
未经允许不得转载:全栈博客园 » 机器学习练习秘籍,高效进步模型功能的有用攻略
 ai艺术字,构思无限,规划新潮流
ai艺术字,构思无限,规划新潮流 哩布哩布ai官网,探究哩布哩布AI官网,敞开智能日子新篇章
哩布哩布ai官网,探究哩布哩布AI官网,敞开智能日子新篇章 机器学习吴恩达作业,从根底到实战
机器学习吴恩达作业,从根底到实战 机器学习 特征提取,特征提取的重要性
机器学习 特征提取,特征提取的重要性












