
 全栈博客园
全栈博客园机器学习中的聚类算法是一种无监督学习技能,旨在将数据点分组或聚类,使得同一组内的数据点互相类似,而不同组之间的数据点则尽或许不同。聚类算法在许多范畴都有运用,如商场细分、图画处理、交际网络剖析等。
以下是几种常见的聚类算法:
1. K均值聚类(Kmeans clustering):这是最简略、最常用的聚类算法之一。它将数据点分配到K个簇中,其间K是用户指定的。算法经过迭代的办法,将每个数据点分配给最近的簇中心(均值),然后更新簇中心。这个进程重复进行,直到簇中心不再明显改动。
2. 层次聚类(Hierarchical clustering):这种算法经过创立一个树状结构(称为层次树)来对数据进行聚类。层次聚类可所以自底向上的(凝集式)或自顶向下的(割裂式)。在凝集式层次聚类中,开始时每个数据点是一个簇,然后根据类似度逐渐兼并相邻的簇,直到一切数据点都兼并为一个簇。在割裂式层次聚类中,开始时一切数据点都在一个簇中,然后根据类似度逐渐割裂成更小的簇。
3. 密度聚类(Densitybased clustering):这种算法根据数据点的密度来聚类。它将数据点分组为高密度区域,这些区域被低密度区域(称为噪声)围住。DBSCAN(DensityBased Spatial Clustering of Applications with Noise)是一种常用的密度聚类算法,它可以辨认出恣意形状的簇,并可以处理噪声数据。
5. 谱聚类(Spectral clustering):这种算法运用数据的谱图理论来聚类。它首要构建一个根据数据点类似度的图,然后核算图的拉普拉斯矩阵的特征值和特征向量。根据特征向量将数据点分组。谱聚类可以处理非球形簇和噪声数据。
6. K中心点聚类(Kmedoids clustering):这种算法类似于K均值聚类,但它运用中位数(称为中心点)而不是均值来表明簇。这使得K中心点聚类对反常值和噪声数据更具鲁棒性。
7. DBSCAN(DensityBased Spatial Clustering of Applications with Noise):这种算法是一种根据密度的聚类算法,它可以发现恣意形状的簇,并可以处理噪声数据。DBSCAN经过界说两个参数(eps和min_samples)来操控簇的密度。eps表明邻域半径,min_samples表明邻域内的最小数据点数。
8. OPTICS(Ordering Points To Identify the Clustering Structure):这种算法是一种根据密度的聚类算法,它可以发现恣意形状的簇,并可以处理噪声数据。OPTICS经过界说一个参数(eps)来操控簇的密度。它可以生成一个聚类次序,使得类似的簇互相接近。
9. BIRCH(Balanced Iterative Reducing and Clustering using Hierarchies):这种算法是一种根据层次聚类的算法,它可以处理大数据集。BIRCH首要将数据点组织成一个树状结构(称为CF树),然后运用层次聚类算法对CF树进行聚类。
10. ISODATA(Iterative SelfOrganizing Data Analysis Technique):这种算法是一种根据迭代的办法,它可以处理大数据集。ISODATA经过迭代的办法更新簇中心和簇的半径,然后将数据点分配给最近的簇。它可以处理噪声数据和反常值。
这些聚类算法各有优缺陷,适用于不同的数据集和聚类使命。挑选适宜的聚类算法取决于数据的特色和聚类的方针。在实践运用中,或许需求测验多种算法,并比较它们的功能,以找到最佳的聚类解决方案。
深化解析机器学习中的聚类算法
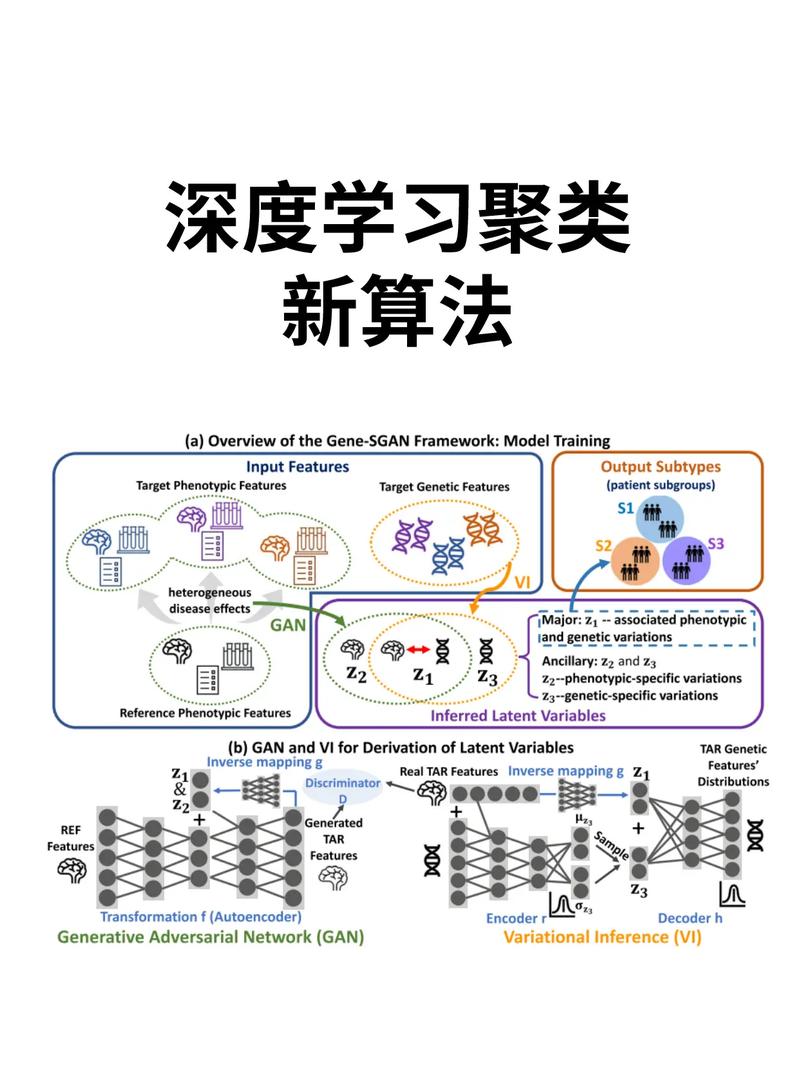
聚类算法是机器学习范畴中的一种无监督学习办法,它经过将数据会集的数据点区分为若干个不同的簇,使得同一簇内的数据点具有较高的类似性,而不同簇之间的数据点具有较高的差异性。本文将深化解析机器学习中的聚类算法,包含其基本原理、常用算法以及运用场景。
一、聚类算法的基本原理
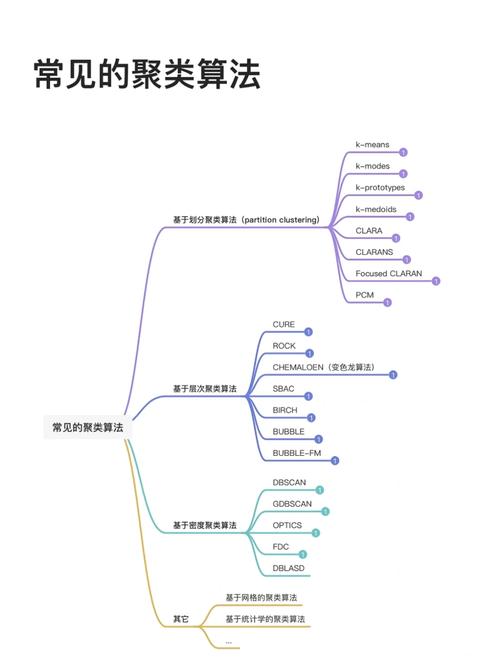
聚类算法的中心思维是将类似的数据点归为一类,而将不类似的数据点分隔。具体来说,聚类算法经过以下过程完成:
挑选聚类算法:根据数据特色和需求挑选适宜的聚类算法。
初始化聚类中心:随机挑选或运用特定办法挑选初始聚类中心。
分配数据点:将每个数据点分配到间隔其最近的聚类中心地点的簇中。
更新聚类中心:核算每个簇的质心,作为新的聚类中心。
迭代:重复过程3和过程4,直到聚类中心不再改动或到达预订的迭代次数。
二、常用聚类算法
在机器学习中,常用的聚类算法首要包含以下几种:
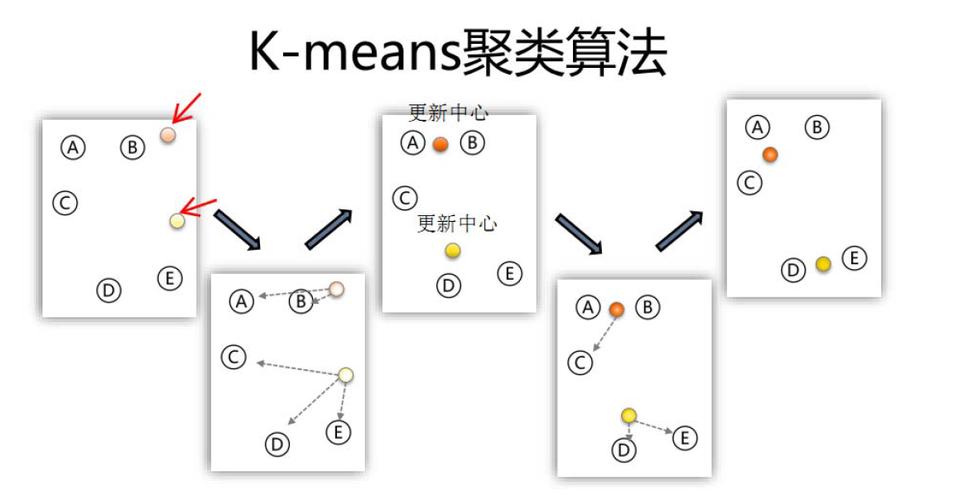
1. K-均值聚类算法
K-均值聚类算法是一种根据区分的聚类算法,其基本思维是将数据集区分为K个簇,使得每个簇内的数据点间隔其质心的间隔之和最小。K-均值聚类算法的长处是简略、易于完成,但缺陷是对初始聚类中心的挑选灵敏,且难以处理非凸形簇。
2. 密度聚类算法
密度聚类算法是一种根据数据点密度的聚类办法,其中心理念是发现数据空间中具有类似密度的区域,并将这些区域区分为不同的簇。密度聚类算法的代表算法有DBSCAN(Density-Based Spatial Clustering of Applications with Noise)和OPTICS(Ordering Points To Identify the Clustering Structure)。
3. 层次聚类算法
层次聚类算法是一种根据层次结构的聚类办法,其基本思维是将数据集逐渐兼并成簇,直到满意中止条件。层次聚类算法的长处是可以处理恣意形状的簇,但缺陷是聚类成果依赖于间隔衡量。
三、聚类算法的运用场景
聚类算法在许多范畴都有广泛的运用,以下罗列一些常见的运用场景:
商场细分:经过聚类剖析,将客户区分为不同的商场细分,以便企业拟定更精准的营销战略。
图画切割:将图画中的像素点区分为不同的区域,以便进行图画处理和剖析。
生物信息学:经过聚类剖析,提醒基因之间的相互作用联系,为疾病诊断和医治供给根据。
反常检测:经过聚类剖析,辨认数据会集的反常值或噪声,进步数据质量。
聚类算法是机器学习范畴中一种重要的无监督学习办法,经过将数据会集的数据点区分为不同的簇,有助于咱们更好地舆解数据的散布和特征。本文介绍了聚类算法的基本原理、常用算法以及运用场景,期望对读者有所协助。
未经允许不得转载:全栈博客园 » 机器学习聚类算法,深化解析机器学习中的聚类算法
 ai艺术字,构思无限,规划新潮流
ai艺术字,构思无限,规划新潮流 哩布哩布ai官网,探究哩布哩布AI官网,敞开智能日子新篇章
哩布哩布ai官网,探究哩布哩布AI官网,敞开智能日子新篇章 机器学习吴恩达作业,从根底到实战
机器学习吴恩达作业,从根底到实战 机器学习 特征提取,特征提取的重要性
机器学习 特征提取,特征提取的重要性










