
 全栈博客园
全栈博客园树立机器学习模型一般包含以下几个进程:
1. 问题界说:清晰你要处理的问题类型,比如是分类、回归、聚类仍是反常检测等。
2. 数据搜集:依据问题界说,搜集相关的数据。数据可所以结构化的(如表格数据)或非结构化的(如图画、文本等)。
3. 数据预处理:对数据进行清洗、转化和规范化,使其适宜机器学习模型。这或许包含处理缺失值、反常值、归一化、特征工程等。
4. 特征挑选:挑选对模型功能有重要影响的特征。这能够经过核算测验、模型挑选等办法完结。
5. 模型挑选:依据问题类型和数据的特性,挑选适宜的机器学习算法。常见的算法包含线性回归、决策树、支撑向量机、神经网络等。
6. 模型练习:运用练习数据来练习模型。这个进程或许需求调整模型的参数,以优化模型的功能。
7. 模型评价:运用测验数据来评价模型的功能。这一般经过核算准确率、召回率、F1分数、均方误差等方针来完结。
8. 模型调优:依据模型评价的成果,调整模型的参数或挑选不同的算法,以改善模型的功能。
9. 模型布置:将练习好的模型布置到出产环境中,使其能够处理实践的数据并做出猜测。
10. 监控和保护:在出产环境中,定时监控模型的功能,并依据需求调整模型或从头练习模型。
树立机器学习模型是一个迭代的进程,或许需求屡次调整和优化,以取得最佳的功能。
浅显易懂:树立机器学习模型的全进程
跟着大数据年代的到来,机器学习技能在各个领域得到了广泛运用。本文将为您具体解析树立机器学习模型的全进程,帮助您更好地了解和运用这一技能。
一、数据预处理
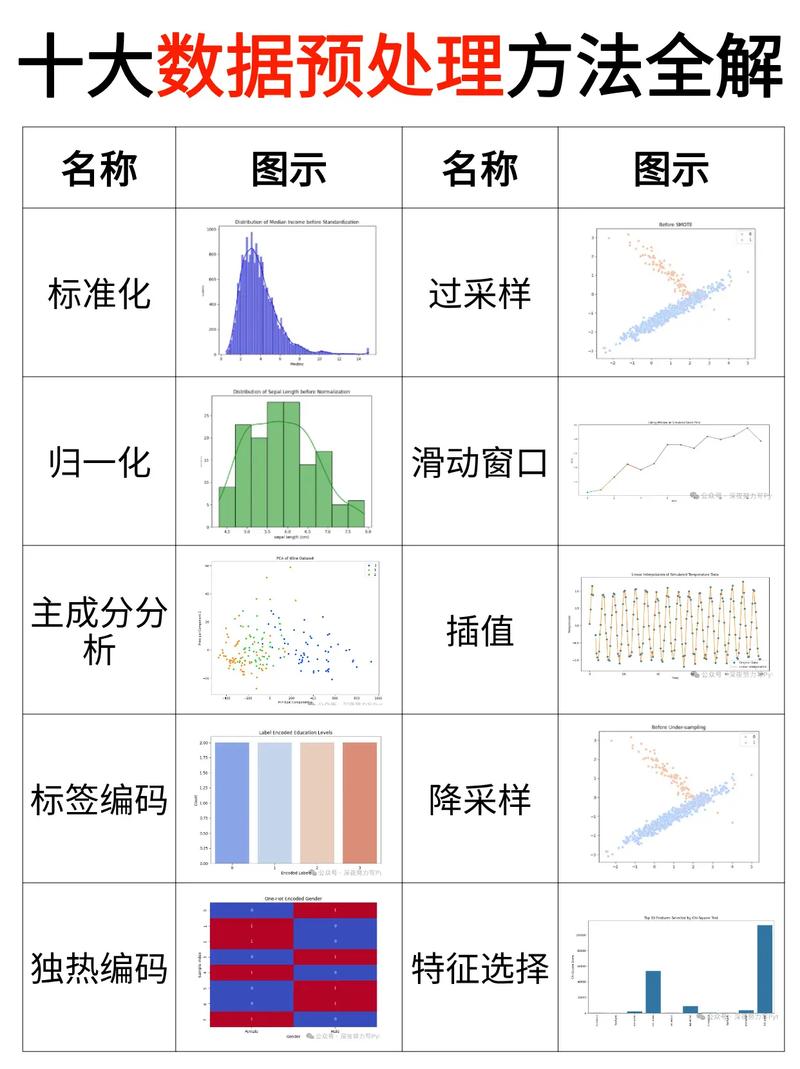
在树立机器学习模型之前,数据预处理是至关重要的进程。这一进程首要包含数据清洗、数据转化和数据归一化。
1. 数据清洗:原始数据往往存在缺失值、反常值和噪声,需求进行清洗。例如,删去重复数据、填充缺失值、去除反常值等。
2. 数据转化:将不同类型的数据转化为适宜模型处理的方式。例如,将分类数据转化为独热编码(One-Hot Encoding),将接连数据转化为区间值等。
3. 数据归一化:将数据缩放到一个固定的规模,如[0,1]或[-1,1],以便模型更好地学习。
二、特征工程与特征挑选

特征工程是机器学习模型树立进程中的关键环节,它触及从原始数据中提取出对猜测方针有用的信息。
1. 特征工程:经过手艺或主动办法,从原始数据中提取出对猜测方针有用的特征。例如,核算平均值、方差、最大值、最小值等核算特征,或运用主成分剖析(PCA)等办法进行降维。
2. 特征挑选:从提取出的特征中挑选对猜测方针最有影响力的特征。常用的特征挑选办法包含单变量特征挑选、递归特征消除(RFE)和根据模型的特征挑选等。
三、模型挑选与练习
1. 线性回归:适用于回归问题,经过拟合数据点与方针变量之间的线性关系进行猜测。
2. 逻辑回归:适用于二分类问题,经过核算概率值进行猜测。
3. 决策树:适用于分类和回归问题,经过树状结构进行猜测。
4. 随机森林:根据决策树的集成学习办法,经过构建多个决策树并归纳它们的猜测成果进行猜测。
5. 支撑向量机(SVM):适用于分类和回归问题,经过寻觅最佳的超平面进行猜测。
6. 神经网络:适用于处理杂乱数据,经过模仿人脑神经元的作业原理进行猜测。
在模型挑选后,需求运用练习数据对模型进行练习。练习进程中,模型会不断调整参数,以最小化猜测值与实在值之间的距离。
四、模型评价与优化
1. 准确率:猜测正确的样本数占总样本数的份额。
2. 准确率:猜测正确的正样本数占一切猜测为正样本的样本数的份额。
3. 召回率:猜测正确的正样本数占一切实践为正样本的样本数的份额。
4. F1分数:准确率和召回率的谐和平均值。
在评价模型后,假如发现模型功能不抱负,能够测验以下办法进行优化:
1. 调整模型参数:经过调整模型参数,如学习率、正则化项等,以进步模型功能。
2. 优化特征工程:从头进行特征工程,提取更有用的特征,以进步模型功能。
3. 测验其他模型:测验其他机器学习模型,比较它们的功能,挑选最优模型。
本文具体介绍了树立机器学习模型的全进程,包含数据预处理、特征工程、模型挑选与练习、模型评价与优化等进程。跟着机器学习技能的不断发展,信任未来会有更多高效、智能的模型运用于实践场景,为咱们的日子带来更多便当。
未经允许不得转载:全栈博客园 » 树立机器学习模型,树立机器学习模型的全进程
 ai官网,探究AI范畴的无限或许——XX智能官网全新上线!
ai官网,探究AI范畴的无限或许——XX智能官网全新上线! 屠戮机器学习,什么是屠戮机器学习?
屠戮机器学习,什么是屠戮机器学习? ai生长归纳点评,技能前进与未来展望
ai生长归纳点评,技能前进与未来展望 ai模型归纳,AI模型归纳概述
ai模型归纳,AI模型归纳概述 ai归纳事例,归纳事例解析
ai归纳事例,归纳事例解析 机器学习准确率,界说、重要性及影响要素
机器学习准确率,界说、重要性及影响要素











