
 全栈博客园
全栈博客园1. 根底包: `base`:R言语的根底包,包含根本的函数和数据结构。 `utils`:供给东西和有用函数,如数据导入/导出、装置包等。 `graphics`:供给根本的图形功用。 `grDevices`:供给图形设备接口,用于创立和保存图形。
2. 数据操作和清洗: `dplyr`:供给了一套数据操作的函数,如`select`, `filter`, `arrange`, `mutate`, `summarize`等,用于数据收拾。 `tidyr`:用于数据清洗,使数据结构整齐。 `data.table`:供给快速的数据操作功用,特别合适处理大型数据集。
3. 计算剖析: `stats`:R言语的根底计算包,包含根本的计算函数。 `car`:供给多种弥补的回归剖析东西。 `lme4`:用于线性混合效应模型。 `survival`:供给生计剖析的功用。
4. 机器学习: `caret`:供给了一整套机器学习作业流程,包含数据切割、模型练习、穿插验证等。 `randomForest`:用于构建随机森林模型。 `xgboost`:供给梯度进步树算法。 `nnet`:用于神经网络。
5. 时刻序列剖析: `forecast`:供给时刻序列猜测的函数。 `tseries`:供给时刻序列剖析的根底函数。 `zoo`:用于时刻序列数据的操作和剖析。
6. 图形和可视化: `ggplot2`:一个根据图形语法的高层次图形体系,用于创立杂乱的图形。 `lattice`:供给了一种根据网格的图形体系。 `plotly`:用于创立交互式图形。 `leaflet`:用于创立交互式地图。
7. 文本剖析: `tm`:供给文本发掘的函数。 `text2vec`:供给文本向量化功用。 `tm.plugin`:供给`tm`包的扩展。
8. 网络剖析: `igraph`:供给网络剖析的功用。 `sna`:用于社会网络剖析。
9. 生物信息学: `Bioconductor`:一个专心于生物信息学的项目,包含很多与基因组学、蛋白质组学等相关的包。
10. 其他: `shiny`:用于创立交互式Web运用程序。 `knitr`:用于动态陈述生成,特别是与R Markdown结合运用。 `ggvis`:与`ggplot2`结合,用于创立交互式图形。
这些包覆盖了R言语在数据剖析、计算建模、机器学习、时刻序列剖析、文本剖析、网络剖析、生物信息学等多个范畴的运用。装置和运用这些包,能够极大地扩展R言语的功用,协助用户完结杂乱的数据剖析使命。
R言语常用包盘点:数据科学家必备利器
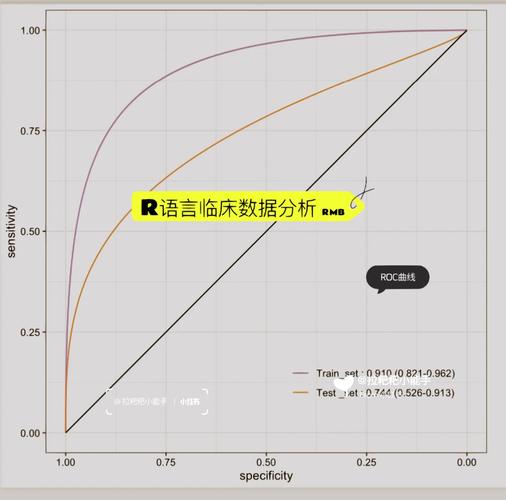
R言语作为一种强壮的计算剖析和图形表明东西,在数据科学范畴有着广泛的运用。R言语具有丰厚的包(packages),这些包为数据科学家供给了强壮的数据处理、剖析和可视化功用。本文将盘点一些R言语中常用的包,协助数据科学家们更好地进行数据科学作业。
一、数据处理包

1. dplyr

2. tidyr

tidyr专心于数据收拾,它能够协助咱们将数据转换成整齐的方式,使得后续的数据剖析愈加简单。
3. data.table

data.table是一个高性能的数据处理包,它供给了快速的行操作和列操作功用,特别合适处理大型数据集。
二、计算剖析包

1. ggplot2
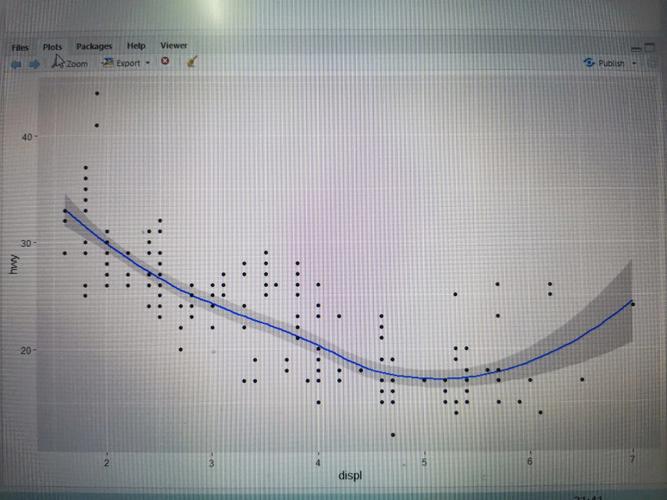
ggplot2是R言语中最受欢迎的图形可视化包之一,它根据Leland Wilkinson的图形语法,能够创立出漂亮且信息丰厚的计算图形。
2. lmtest

lmtest供给了对线性模型进行确诊和查验的函数,能够协助咱们评价模型的拟合程度。
3. car

car包供给了许多用于线性模型剖析的函数,包含模型确诊、方差剖析等。
三、机器学习包
1. caret

caret是一个综合性的机器学习包,它供给了许多机器学习算法的完成,以及模型练习、评价和调优的东西。
2. randomForest

randomForest是一个根据随机森林算法的机器学习包,它适用于分类和回归问题。
3. xgboost
xgboost是一个根据梯度进步决策树的机器学习包,它在许多机器学习比赛中取得了优异的成果。
四、数据可视化包
1. plotly

plotly是一个交互式可视化包,它能够将R言语中的数据转换为HTML和JavaScript,然后完成网页上的交互式图表。
2. shiny
shiny是一个根据R言语的Web运用结构,它能够协助咱们快速构建交互式的Web运用。
3. highcharter
highcharter是一个根据Highcharts的R包,它供给了丰厚的图表类型,能够创立出漂亮的计算图表。
五、其他常用包

除了上述包之外,还有一些其他常用的R包,以下罗列一些:
1. lubridate
lubridate是一个处理日期和时刻的包,它供给了简练的语法和丰厚的函数,能够轻松地对日期和时刻进行操作。
2. tidycensus

tidycensus是一个处理人口普查数据的包,它能够协助咱们将人口普查数据转换成整齐的方式。
3. knitr
knitr是一个用于文档和陈述的包,它能够将R代码和文本混合在一起,生成漂亮的文档。
以上是R言语中一些常用的包,这些包能够协助数据科学家们更好地进行数据处理、剖析和可视化。把握这些包的运用,将有助于进步数据科学作业的功率和质量。
未经允许不得转载:全栈博客园 » r言语常用包,数据科学家必备利器
 php文件用什么软件翻开,挑选适宜的软件
php文件用什么软件翻开,挑选适宜的软件 java生成二维码,从根底到高档运用
java生成二维码,从根底到高档运用 go bigger,怎么完结个人和工作的“Go Bigger”
go bigger,怎么完结个人和工作的“Go Bigger”









