
 全栈博客园
全栈博客园1. 监督学习:监督学习是一种机器学习办法,它运用符号的练习数据来练习模型,以便模型可以对未符号的数据进行猜测。监督学习可以分为两类:分类和回归。2. 非监督学习:非监督学习是一种机器学习办法,它运用未符号的数据来练习模型,以便模型可以发现数据中的形式和结构。非监督学习可以分为两类:聚类和降维。3. 半监督学习:半监督学习是一种机器学习办法,它运用符号和未符号的数据来练习模型,以便模型可以从符号数据中学习,一起从未符号数据中获取更多的信息。4. 强化学习:强化学习是一种机器学习办法,它经过与环境交互来学习最优战略。强化学习一般用于处理决议计划问题,如游戏、机器人操控等。5. 决议计划树:决议计划树是一种用于分类和回归的机器学习算法。它经过一系列的决议计划规矩来对数据进行分类或回归。6. 随机森林:随机森林是一种集成学习算法,它经过构建多个决议计划树并取它们的平均值来进步模型的准确性和泛化才能。7. 支撑向量机(SVM):支撑向量机是一种用于分类和回归的机器学习算法。它经过寻觅一个超平面来最大化不同类别之间的距离,然后完成分类或回归。8. 神经网络:神经网络是一种模仿人脑神经元结构的机器学习算法。它由多个层组成,每层包含多个神经元,经过前向传达和反向传达算法来练习模型。9. 深度学习:深度学习是一种根据神经网络的机器学习办法,它运用多层神经网络来学习数据中的杂乱形式和结构。深度学习在图像识别、自然语言处理等范畴取得了明显的效果。
这些仅仅机器学习技法中的一部分,还有许多其他的算法和技能可以用于处理不同的问题。挑选适宜的技法取决于问题的类型、数据的特性和模型的功能要求。
机器学习技法概述
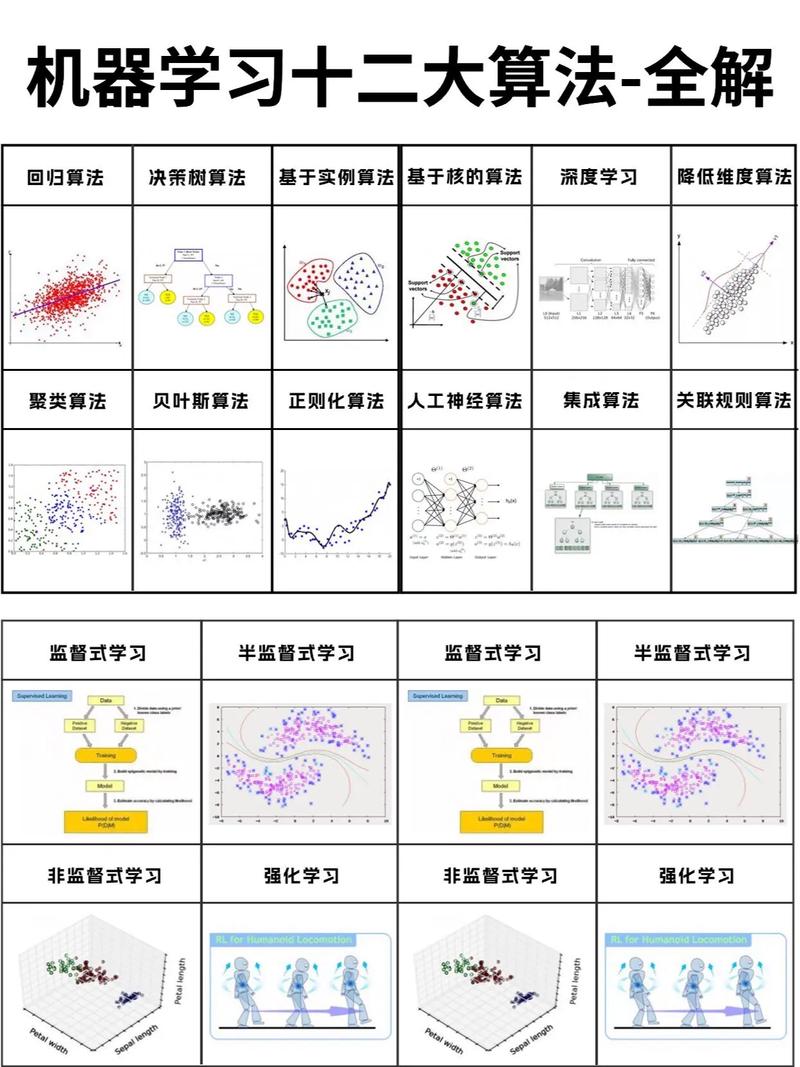
跟着大数据年代的到来,机器学习技能在各个范畴得到了广泛使用。机器学习技法是机器学习范畴的一个重要分支,它涵盖了从数据预处理到模型评价的整个进程。本文将具体介绍机器学习技法的基本概念、常用办法和使用场景。
数据预处理
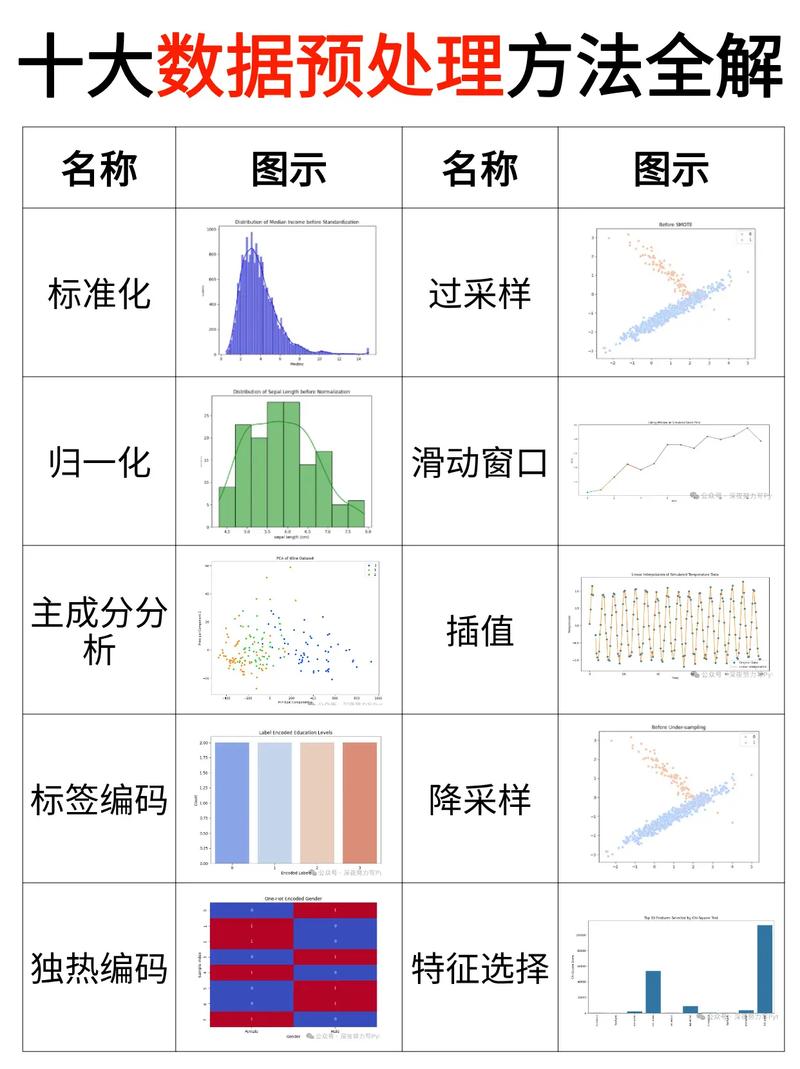
数据预处理是机器学习进程中的第一步,其意图是进步数据质量,为后续的模型练习供给杰出的数据根底。数据预处理首要包含以下进程:
数据清洗:去除重复数据、处理缺失值、纠正过错数据等。
数据转化:将不同类型的数据转化为同一类型,如将类别型数据转化为数值型数据。
特征工程:经过特征挑选、特征提取等办法,从原始数据中提取出对模型练习有协助的特征。
特征挑选与提取
特征挑选和提取是机器学习技法中的关键环节,它们直接影响着模型的功能。以下是几种常用的特征挑选和提取办法:
特征挑选:经过评价特征的重要性,挑选对模型练习有协助的特征。
特征提取:经过将原始数据转化为新的特征,进步模型的功能。
主成分剖析(PCA):经过降维,将原始数据转化为新的特征空间。
特征嵌入:将原始数据转化为低维空间,一起保存原始数据的结构。
模型练习

模型练习是机器学习技法中的中心环节,其意图是经过学习数据中的规则,构建出可以对不知道数据进行猜测的模型。以下是几种常用的模型练习办法:
监督学习:经过已知的输入和输出数据,学习出输入和输出之间的联系。
无监督学习:经过剖析数据中的规则,发现数据中的躲藏结构。
半监督学习:结合监督学习和无监督学习,使用少数标示数据和很多未标示数据。
强化学习:经过与环境交互,学习出最优战略。
模型评价
模型评价是机器学习技法中的关键环节,其意图是评价模型的功能,为后续的模型优化供给根据。以下是几种常用的模型评价办法:
准确率:模型猜测正确的样本数与总样本数的比值。
召回率:模型猜测正确的正样本数与实践正样本数的比值。
F1值:准确率和召回率的谐和平均值。
ROC曲线:经过制作不同阈值下的真阳性率与假阳性率曲线,评价模型的功能。
常见机器学习算法

在机器学习技法中,有许多经典的算法,以下罗列几种常见的算法:
线性回归:经过学习输入和输出之间的联系,猜测接连值。
逻辑回归:经过学习输入和输出之间的联系,猜测离散值。
支撑向量机(SVM):经过寻觅最优的超平面,将不同类其他数据分隔。
决议计划树:经过递归地区分数据,构建出决议计划树模型。
随机森林:经过集成多个决议计划树,进步模型的功能。
机器学习技法是机器学习范畴的一个重要分支,它涵盖了从数据预处理到模型评价的整个进程。把握机器学习技法,有助于咱们更好地了解和使用机器学习技能。本文对机器学习技法的基本概念、常用办法和使用场景进行了扼要介绍,期望对读者有所协助。
未经允许不得转载:全栈博客园 » 机器学习技法,机器学习技法概述
 ai官网,探究AI范畴的无限或许——XX智能官网全新上线!
ai官网,探究AI范畴的无限或许——XX智能官网全新上线! 屠戮机器学习,什么是屠戮机器学习?
屠戮机器学习,什么是屠戮机器学习? ai生长归纳点评,技能前进与未来展望
ai生长归纳点评,技能前进与未来展望 ai模型归纳,AI模型归纳概述
ai模型归纳,AI模型归纳概述 ai归纳事例,归纳事例解析
ai归纳事例,归纳事例解析 机器学习准确率,界说、重要性及影响要素
机器学习准确率,界说、重要性及影响要素











