
 全栈博客园
全栈博客园1. 监督学习:这种学习方法从符号的练习数据中学习,以便对新数据进行猜测或分类。常见的监督学习算法包含线性回归、逻辑回归、支撑向量机、决议计划树和随机森林等。
2. 无监督学习:与监督学习不同,无监督学习从未符号的数据中学习,以便发现数据中的形式和结构。常见的无监督学习算法包含聚类、降维和相关规则学习等。
3. 强化学习:这种学习方法经过与环境的交互来学习,以最大化累积奖赏。强化学习在游戏、机器人操控和引荐体系等范畴有广泛运用。
4. 深度学习:深度学习是一种特别的机器学习方法,它运用神经网络来学习数据中的杂乱形式。深度学习在图像辨认、语音辨认和自然语言处理等范畴取得了明显的效果。
5. 特征工程:特征工程是机器学习中的一个重要过程,它涉及到从原始数据中提取有用的特征,以便进步模型的功能。
6. 模型评价:在机器学习中,模型评价是一个重要的过程,它涉及到运用测验数据来评价模型的功能。常见的模型评价目标包含准确率、召回率、F1分数和ROC曲线等。
7. 过拟合与欠拟合:过拟合是指模型在练习数据上体现杰出,但在新数据上体现欠安的状况。欠拟合则是指模型在练习数据上体现欠安,一般是因为模型过于简略。
8. 穿插验证:穿插验证是一种用于评价模型泛化才能的技巧,它经过将数据分红多个子集来进行练习和测验。
9. 超参数调整:超参数是模型参数的一部分,它们不是经过练习数据学习得到的,而是需求人工设置的。超参数调整是进步模型功能的关键过程。
10. 集成学习:集成学习是一种经过组合多个模型来进步猜测功能的技能。常见的集成学习算法包含Bagging、Boosting和Stacking等。
11. 正则化:正则化是一种用于避免过拟合的技能,它经过在丢失函数中增加一个赏罚项来完成。
12. 搬迁学习:搬迁学习是一种将一个范畴学习到的常识运用到另一个范畴的技能,它一般用于处理数据缺乏的问题。
这些仅仅机器学习的一些根底常识,实际上还有许多其他的主题和算法需求学习。假如你对机器学习感兴趣,可以阅览相关的书本、论文和教程来深化了解。
机器学习入门攻略:从根底到实践

一、什么是机器学习?
机器学习是一种使计算机体系可以从数据中学习并做出决议计划或猜测的技能。它经过算法剖析数据,从中提取形式和常识,然后完成自动化决议计划。
二、机器学习的分类
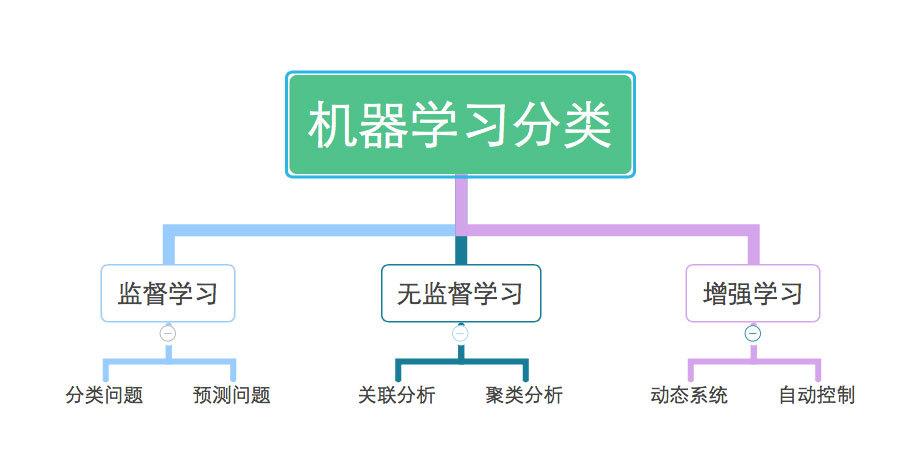
依据学习方法和运用场景,机器学习可以分为以下几类:
监督学习:经过已符号的练习数据来练习模型,使其可以对不知道数据进行猜测。
无监督学习:经过未符号的数据来发现数据中的形式和结构。
强化学习:经过与环境交互,学习最优战略以完成目标。
三、机器学习的根本流程
机器学习的根本流程包含以下过程:
数据搜集:搜集相关范畴的数据,为后续剖析供给根底。
数据预处理:对搜集到的数据进行清洗、转化和归一化等操作,进步数据质量。
特征工程:从原始数据中提取有用的特征,为模型练习供给支撑。
模型挑选:依据实际问题挑选适宜的机器学习算法。
模型练习:运用练习数据对模型进行练习,使其可以学习数据中的规则。
模型评价:运用测验数据对模型进行评价,判别其功能。
模型优化:依据评价成果对模型进行调整,进步其功能。
四、常用机器学习算法

线性回归:用于猜测接连值。
逻辑回归:用于猜测离散值,如二分类问题。
支撑向量机(SVM):用于分类和回归问题。
决议计划树:用于分类和回归问题,易于了解和解说。
随机森林:依据决议计划树的集成学习方法,进步猜测精度。
朴素贝叶斯:依据贝叶斯定理的分类算法,适用于文本分类。
神经网络:模仿人脑神经元衔接的算法,适用于杂乱问题。
五、机器学习实践

以下是一个简略的机器学习实践事例:
搜集数据:从网上下载一个气候数据集。
数据预处理:对数据进行清洗、转化和归一化等操作。
特征工程:从原始数据中提取有用的特征,如温度、湿度、风速等。
模型挑选:挑选一个适宜的机器学习算法,如线性回归。
模型练习:运用练习数据对模型进行练习。
模型评价:运用测验数据对模型进行评价,判别其功能。
模型优化:依据评价成果对模型进行调整,进步其
未经允许不得转载:全栈博客园 » 机器学习笔记,从根底到实践
 ai归纳事例,归纳事例解析
ai归纳事例,归纳事例解析 机器学习准确率,界说、重要性及影响要素
机器学习准确率,界说、重要性及影响要素 ai绘画绝色佳人,科技与艺术的完美交融
ai绘画绝色佳人,科技与艺术的完美交融 机器学习实战源代码
机器学习实战源代码 资料机器学习,改造资料科学的研讨与开发
资料机器学习,改造资料科学的研讨与开发









