
 全栈博客园
全栈博客园机器学习(Machine Learning)的中心在于让核算机能够从数据中学习并做出决议计划或猜测。以下是机器学习的一些中心概念和组成部分:
1. 数据:机器学习依赖于很多的数据。这些数据可所以结构化的(如表格中的数据),也可所以非结构化的(如图画、文本、音频等)。
2. 特征:从数据中提取的特征是机器学习模型了解数据的根底。特征挑选和特征工程是进步模型功能的关键步骤。
3. 模型:机器学习模型是学习数据中的形式和联系的算法。这些模型可所以监督学习、无监督学习或强化学习等。
4. 练习:经过运用练习数据,模型学习怎么从输入数据中猜测输出。练习进程包含调整模型参数,以最小化猜测差错。
5. 评价:在练习完成后,模型需求在未见过的新数据上进行评价,以验证其泛化才能。常用的评价方针包含准确率、召回率、F1分数等。
6. 优化:为了进步模型的功能,或许需求优化模型参数、特征挑选、模型结构等。
7. 算法:机器学习算法是构建模型的根底。常见的算法包含线性回归、决议计划树、支撑向量机、神经网络等。
8. 理论:机器学习的理论根底包含统计学、概率论、信息论、优化理论等。
9. 使用:机器学习在许多范畴都有使用,如自然语言处理、核算机视觉、语音辨认、引荐体系、金融猜测等。
10. 道德和隐私:跟着机器学习的广泛使用,道德和隐私问题也日益突出。保证数据的安全性和模型的公平性是机器学习研讨的重要方向。
11. 继续学习:在实际国际使用中,模型或许需求不断更新和学习新数据,以习惯不断改变的环境。
12. 解释性:关于许多使用,模型的可解释性也很重要。了解模型怎么做出决议计划有助于树立信赖并发现潜在的问题。
机器学习的中心是树立一个能够从数据中学习并做出猜测或决议计划的体系。这需求归纳考虑数据、特征、模型、算法、评价、优化等多个方面。
机器学习的界说与布景
机器学习(Machine Learning,ML)是人工智能(Artificial Intelligence,AI)的一个重要分支,它使核算机体系能够从数据中学习并做出决议计划或猜测,而无需显式编程。这一范畴的研讨始于20世纪50年代,跟着核算才能的进步和大数据年代的到来,机器学习得到了迅速发展。
机器学习的基本概念
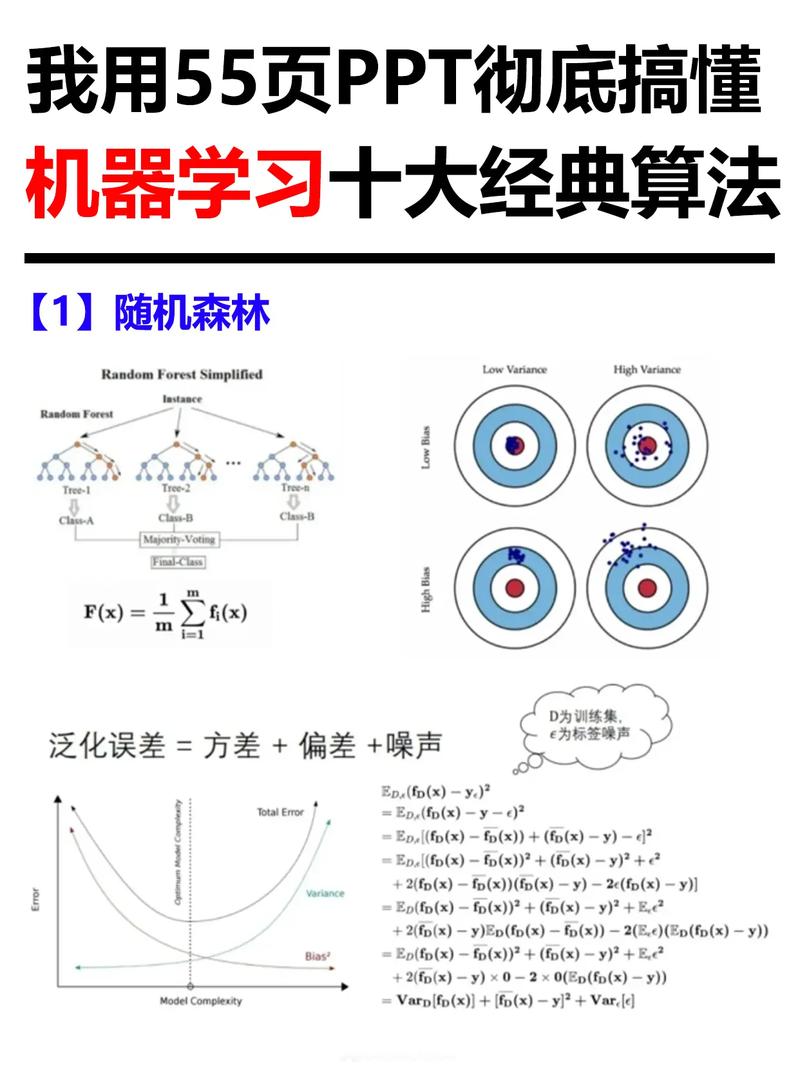
机器学习的基本概念包含算法、模型、特征和练习数据。算法是机器学习模型的中心,它决议了模型怎么从数据中学习。模型是算法在数据上运转后的效果,它能够对新的数据进行猜测。特征是数据中的特点,它们关于模型的猜测才能至关重要。练习数据是用于练习模型的原始数据集。
机器学习的分类
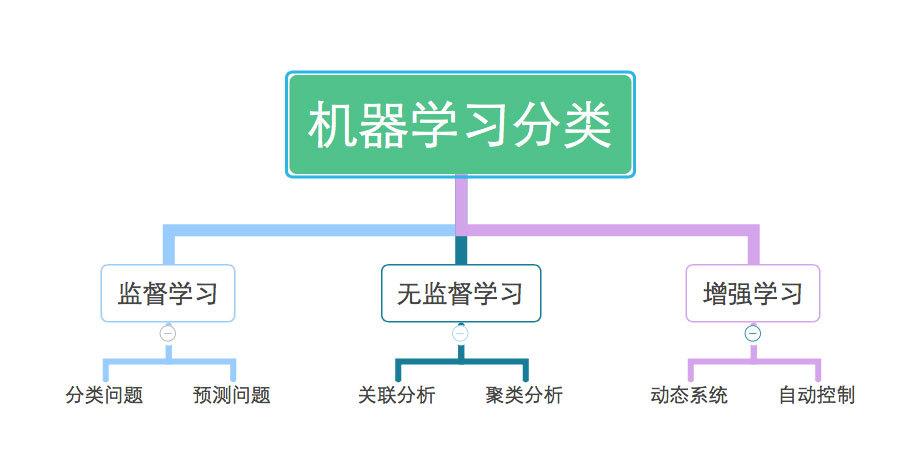
机器学习能够依据学习方法和使用场景进行分类。按学习方法,能够分为监督学习(Supervised Learning)、无监督学习(Unsupervised Learning)和半监督学习(Semi-supervised Learning)。监督学习需求标示的练习数据,无监督学习则不需求标示数据,半监督学习则介于两者之间。按使用场景,能够分为分类、回归、聚类、降维等。
监督学习
无监督学习

无监督学习旨在发现数据中的内涵结构和形式。它不需求标示数据,经过剖析数据之间的相似性或差异性来提醒数据中的规则。常见的无监督学习算法包含K-均值聚类、层次聚类、主成分剖析(PCA)、自编码器等。
半监督学习

机器学习的使用

自然语言处理:机器学习在语音辨认、机器翻译、情感剖析等方面发挥着重要效果。
核算机视觉:机器学习在图画辨认、方针检测、人脸辨认等范畴取得了明显效果。
引荐体系:机器学习能够协助引荐体系更好地了解用户偏好,进步引荐质量。
金融风控:机器学习在信誉评价、反诈骗、危险操控等方面发挥着重要效果。
医疗确诊:机器学习能够协助医师进行疾病确诊,进步确诊准确率。
智能交通:机器学习在自动驾驶、交通流量猜测、智能交通信号操控等方面具有广泛使用。
机器学习的应战与未来

虽然机器学习取得了巨大进步,但仍面对一些应战。首要,数据质量对机器学习模型的功能至关重要,而实际国际中的数据往往存在噪声和缺失。其次,模型的可解释性是一个重要问题,用户需求了解模型的决议计划进程。此外,算法的公平性和隐私维护也是需求重视的问题。
未来,机器学习的研讨将愈加重视以下几个方面:
数据质量与数据增强:进步数据质量,探究数据增强技能,以应对数据噪声和缺失问题。
模型可解释性:研讨可解释的机器学习模型,进步用户对模型决议计划进程的了解。
算法公平性与隐私维护:保证算法的公平性,维护用户隐私。
跨范畴学习:探究跨范畴学习技能,进步模型在不同范畴的泛化才能。
经过以上内容,咱们能够看到机器学习在各个范畴的广泛使用及其面对的应战。跟着技能的不断进步,咱们有理由信任,机器学习将在未来发挥愈加重要的效果。
未经允许不得转载:全栈博客园 » 机器学习的中心,机器学习的界说与布景
 ai归纳事例,归纳事例解析
ai归纳事例,归纳事例解析 机器学习准确率,界说、重要性及影响要素
机器学习准确率,界说、重要性及影响要素 ai绘画绝色佳人,科技与艺术的完美交融
ai绘画绝色佳人,科技与艺术的完美交融 机器学习实战源代码
机器学习实战源代码 资料机器学习,改造资料科学的研讨与开发
资料机器学习,改造资料科学的研讨与开发










