
 全栈博客园
全栈博客园1. DataLight DataLight 是一个开源的大数据运维办理渠道,用于简化和自动化大数据服务的布置、办理和监控。它供给了一套全面的东西来办理大数据生态体系,旨在协助企业完成简练、快速地构建 OLAP 与 OLTP 一致的事务渠道。
2. Apache Atlas Apache Atlas 是一个数据办理开源结构,支撑数据办理团队可以在整个安排中协作办理大数据财物和元数据。它为杂乱的企业数据供给了可扩展的数据模型和高度集成的办理处理方案。
3. ERD Online ERD Online 是全球第一个开源、免费在线数据建模、元数据办理渠道。它供给简略易用的元数据规划、联系图规划、SQL查询等功能,辅以版别、导入、导出、数据源、SQL解析、审计、团队协作等功能,便利快速、安全地办理数据库中的元数据。
4. Apache Hadoop Apache Hadoop 是一个分布式体系根底架构,由Apache基金会开发。它答应运用简略的编程模型在跨多台核算机的集群上对大规模数据集进行分布式处理。Hadoop已成为大数据处理的柱石。
5. Apache Spark Apache Spark 是一个快速、通用、开源的大数据处理引擎,它供给了高档API,支撑Scala、Java、Python和R等言语。Spark在内存核算方面表现出色,适宜处理需求快速呼应的大数据处理使命。
6. Apache Flink Apache Flink 是一个开源流处理结构,用于处理有界和无界的数据流。它供给了高吞吐量、低推迟的流处理才能,而且支撑事情驱动的运用。
7. Apache HBase Apache HBase 是一个分布式的、可扩展的、支撑列的存储体系,模型类似于Google的Bigtable。它运用Hadoop文件体系(HDFS)作为其文件存储,适宜非结构化和半结构化数据的存储。
8. Qualitis Qualitis 是一个支撑多种异构数据源的质量校验、告诉、办理服务的数据质量办理渠道,用于处理事务体系运转、数据中心建造及数据办理过程中的各种数据质量问题。
这些渠道各有特色,您可以依据详细需求挑选适宜的开源大数据办理渠道。
开源大数据办理渠道:构建高效数据生态的要害
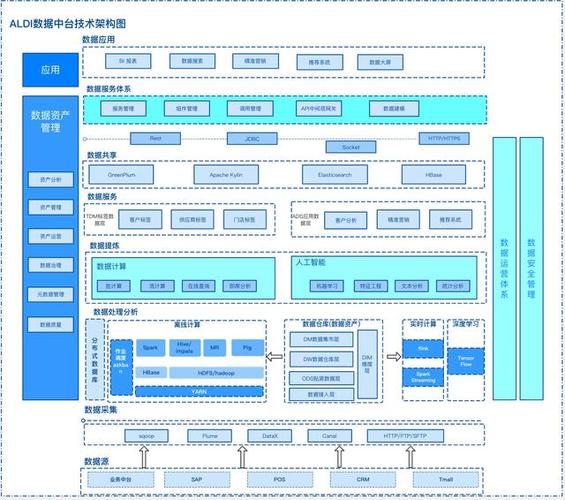
跟着大数据技能的飞速开展,企业对数据的办理和剖析需求日益增长。开源大数据办理渠道作为大数据生态的重要组成部分,为企业供给了高效、安稳、可扩展的数据办理处理方案。本文将深入探讨开源大数据办理渠道的特色、优势以及运用场景。
一、开源大数据办理渠道概述
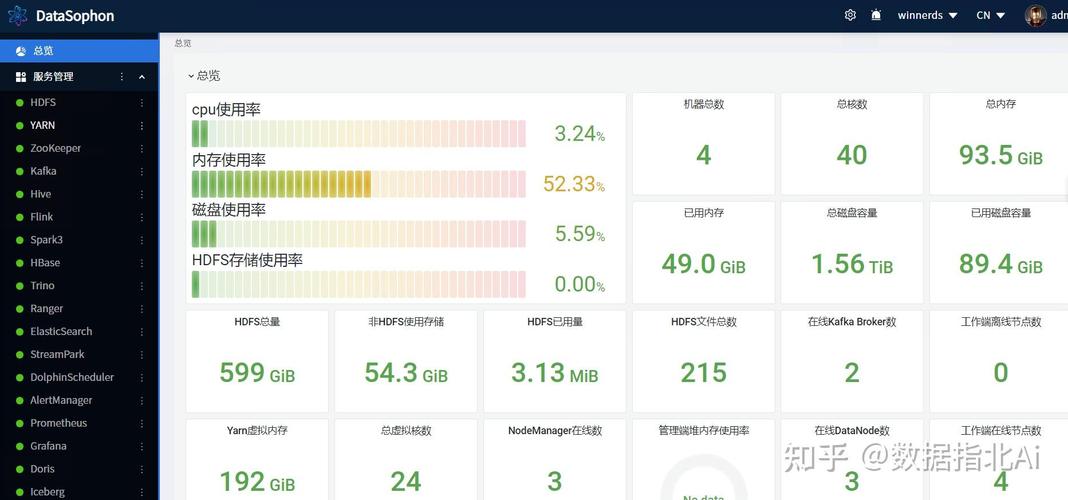
开源大数据办理渠道是指根据开源协议,由社区或企业一起维护的大数据办理东西。它涵盖了数据收集、存储、处理、剖析和可视化等多个环节,旨在协助企业完成数据的高效办理和运用。常见的开源大数据办理渠道包含Apache Hadoop、Apache Spark、Apache Flink等。
二、开源大数据办理渠道的特色
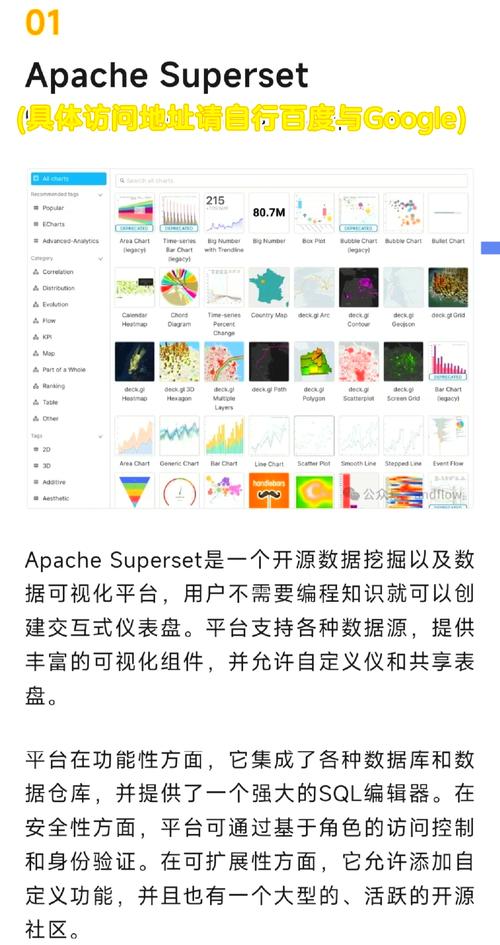
1. 开源:开源大数据办理渠道遵从开源协议,用户可以免费获取和运用,降低了企业的本钱。
2. 高效:开源大数据办理渠道具有高性能、高并发、高可扩展性等特色,可以满意大规模数据处理需求。
3. 灵敏:开源大数据办理渠道支撑多种数据源和数据处理技能,可依据企业需求进行定制化开发。
4. 安全:开源大数据办理渠道重视数据安全和隐私维护,供给多种安全机制,保证数据安全。
三、开源大数据办理渠道的优势
1. 降低本钱:开源大数据办理渠道免费运用,企业无需付出昂扬的软件答应费用。
2. 进步功率:开源大数据办理渠道具有高性能、高并发等特色,可以快速处理海量数据,进步数据处理功率。
3. 促进立异:开源大数据办理渠道鼓舞用户参加社区建造,推进技能立异和产品迭代。
4. 生态丰厚:开源大数据办理渠道具有巨大的社区和丰厚的生态资源,为用户供给全方位的技能支撑。
四、开源大数据办理渠道的运用场景
1. 数据仓库:开源大数据办理渠道可构建高效、安稳的数据仓库,为企业供给数据剖析和决议计划支撑。
2. 实时核算:开源大数据办理渠道支撑实时数据处理,适用于金融、电商、物联网等范畴。
3. 大数据剖析:开源大数据办理渠道可进行大规模数据发掘和剖析,为企业供给洞察力。
4. 机器学习:开源大数据办理渠道支撑机器学习算法,助力企业完成智能化转型。
开源大数据办理渠道在降低本钱、进步功率、促进立异等方面具有明显优势,已成为大数据生态的重要组成部分。跟着大数据技能的不断开展,开源大数据办理渠道将持续为企业供给高效、安稳、可扩展的数据办理处理方案,助力企业完成数据驱动的开展。
未经允许不得转载:全栈博客园 » 开源大数据办理渠道,构建高效数据生态的要害
 什么是云核算概念,什么是云核算?
什么是云核算概念,什么是云核算? 云核算与大数据的差异
云核算与大数据的差异 区块链是啥意思,区块链是什么意思?揭秘其中心概念与优势
区块链是啥意思,区块链是什么意思?揭秘其中心概念与优势 云核算开展,云核算的兴起与演化
云核算开展,云核算的兴起与演化 云核算作业方向,云核算作业远景概述
云核算作业方向,云核算作业远景概述 开源邮件体系,企业信息交流的得力助手
开源邮件体系,企业信息交流的得力助手 开源视频会议软件,助力长途协作新时代
开源视频会议软件,助力长途协作新时代 区块链版权存证
区块链版权存证











