
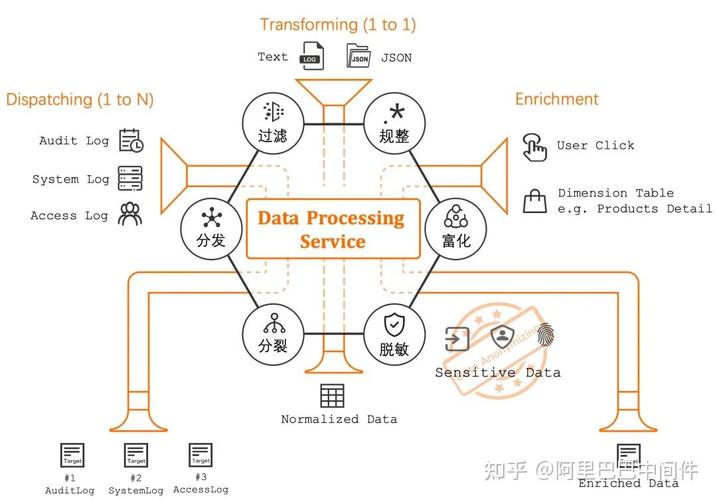
 全栈博客园
全栈博客园1. 《机器学习实战:依据ScikitLearn、Keras和TensorFlow》第3版资源下载: 该库房供给了PDF电子书和配套的代码及数据,适用于对机器学习感兴趣的初学者和进阶者。一切代码已从TensorFlow 1.x迁移到TensorFlow 2.x,而且大部分初级TensorFlow代码已被更简略的Keras代码所代替。详细信息和下载地址能够参阅以下。
2. 10个经典机器学习实战项目免费共享: 该文章共享了10个经典的机器学习相关实战项目,包含完好的数据集与项目分析源码。感兴趣的小伙伴能够在文末获取更多学习资源。详细信息和获取办法能够参阅以下。
3. 机器学习实战源码和数据集下载: 该资源供给了《机器学习实战》的源码和数据集,包含作者在书中用于示例和操练的代码以及相关数据集。详细信息和下载地址能够参阅以下。
4. 机器学习项目实战 项目详解 数据集 完好源码 项目陈述: 该专栏整理了《机器学习项目实战事例》,内包含了各种不同的入门级机器学习项目,包含项目原理以及源码,每一个项目实例都顺便有完好的代码 数据集。详细信息和获取办法能够参阅以下。
期望这些资源对你有所协助!如果有任何问题或需求进一步的协助,请随时奉告。
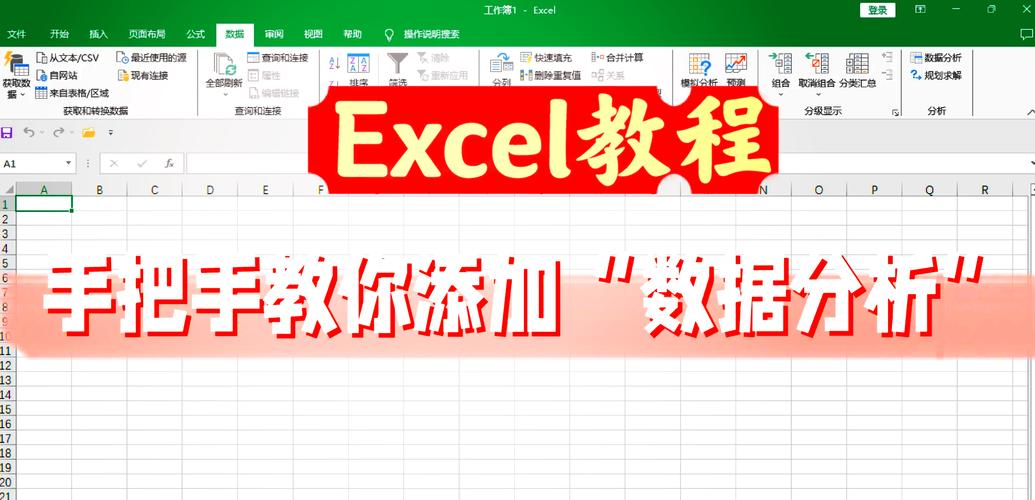
机器学习实战:数据预处理与模型构建全解析
一、数据预处理的重要性

数据预处理是机器学习过程中的重要环节,它直接影响着模型的功能和准确性。数据预处理首要包含以下过程:
1. 数据清洗

数据清洗是指对原始数据进行清洗,去除噪声、缺失值、异常值等。数据清洗的首要办法有:
删去缺失值:能够运用均值、中位数、众数等办法填充缺失值,或许直接删去含有缺失值的样本。
处理异常值:能够运用箱线图、Z-score等办法辨认异常值,并进行处理,如删去、替换等。
去除噪声:能够经过滑润、滤波等办法去除数据中的噪声。
2. 数据转化

数据转化是指将原始数据转化为适宜机器学习模型处理的方式。常见的转化办法有:
归一化:将数据缩放到[0,1]或[-1,1]范围内,消除量纲的影响。
标准化:将数据转化为均值为0,标准差为1的方式,消除量纲和标准的影响。
离散化:将接连型数据转化为离散型数据,便于模型处理。
3. 数据集成
数据集成是指将多个数据源中的数据兼并为一个数据集。数据集成的首要办法有:
兼并:将多个数据源中的数据兼并为一个数据集。
衔接:将多个数据源中的数据经过键值对进行衔接。
采样:从原始数据会集抽取部分数据作为样本。
二、模型构建

模型构建是机器学习实战中的中心环节,首要包含以下过程:
1. 模型挑选
依据实际问题挑选适宜的机器学习模型。常见的机器学习模型有:
线性回归:用于回归问题。
逻辑回归:用于分类问题。
决策树:用于回归和分类问题。
支撑向量机:用于分类问题。
神经网络:用于回归和分类问题。
2. 模型练习

运用练习数据对选定的模型进行练习。练习过程中,模型会不断调整参数,以最小化猜测差错。
3. 模型评价
运用测试数据对练习好的模型进行评价,以判别模型的功能。常见的评价目标有:
准确率:猜测正确的样本数占总样本数的份额。
召回率:猜测正确的正样本数占一切正样本数的份额。
F1值:准确率和召回率的谐和平均值。
三、实战事例
以下是一个简略的机器学习实战事例,运用Python完成线性回归模型,猜测房价。
1. 导入必要的库

```python
import numpy as np
import pandas as pd
from sklearn.metrics import mean_squared_error
2. 加载数据
```python
data = pd.read_csv('house_prices.csv')
X = data[['area', 'bedrooms', 'bathrooms']]
y = data['price']
3. 数据预处理

```python
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
4. 模型练习
```python
未经允许不得转载:全栈博客园 » 机器学习实战 数据,数据预处理与模型构建全解析
 美团机器学习,驱动本地日子服务渠道的才智引擎
美团机器学习,驱动本地日子服务渠道的才智引擎 图画辨认 机器学习,技能革新与未来展望
图画辨认 机器学习,技能革新与未来展望 ai绘画东西,敞开艺术创造新篇章
ai绘画东西,敞开艺术创造新篇章 小学生学习机器人,小小机器人迷的奇幻之旅——小学生学习机器人的故事
小学生学习机器人,小小机器人迷的奇幻之旅——小学生学习机器人的故事 ai作图软件,敞开构思无限的新时代
ai作图软件,敞开构思无限的新时代 机器学习项目实战,从入门到通晓
机器学习项目实战,从入门到通晓 ai敞开渠道,赋能立异,推进智能年代开展
ai敞开渠道,赋能立异,推进智能年代开展










