
 全栈博客园
全栈博客园当然能够,我能够协助你处理和剖析数据。请告诉我你需求进行哪种类型的数据处理或剖析,以及你期望得到什么样的成果。这样我能够更好地了解你的需求并供给相应的协助。
Python数据处理:高效剖析与可视化
在当今数据驱动的国际中,Python已成为数据处理和剖析的强壮东西。它供给了丰厚的库和结构,如Pandas、NumPy、Matplotlib和Scikit-learn,使得数据科学家和工程师能够轻松地处理、剖析和可视化数据。本文将讨论Python在数据处理中的要害概念、常用库以及一些实践使用事例。
挑选适宜的Python库
- Pandas:一个强壮的数据剖析东西,供给了数据结构DataFrame,用于存储和操作表格数据。
- NumPy:一个根底的科学核算库,供给了多维数组目标以及一系列数学函数。
- Matplotlib:一个用于数据可视化的库,能够创立各种图表和图形。

- Scikit-learn:一个机器学习库,供给了多种算法和东西,用于数据发掘和数据剖析。
数据导入与导出
- CSV:一种简略的文本文件格局,常用于数据交换。
- Excel:一种电子表格格局,能够存储很多数据。
- JSON:一种轻量级的数据交换格局,易于阅览和编写。
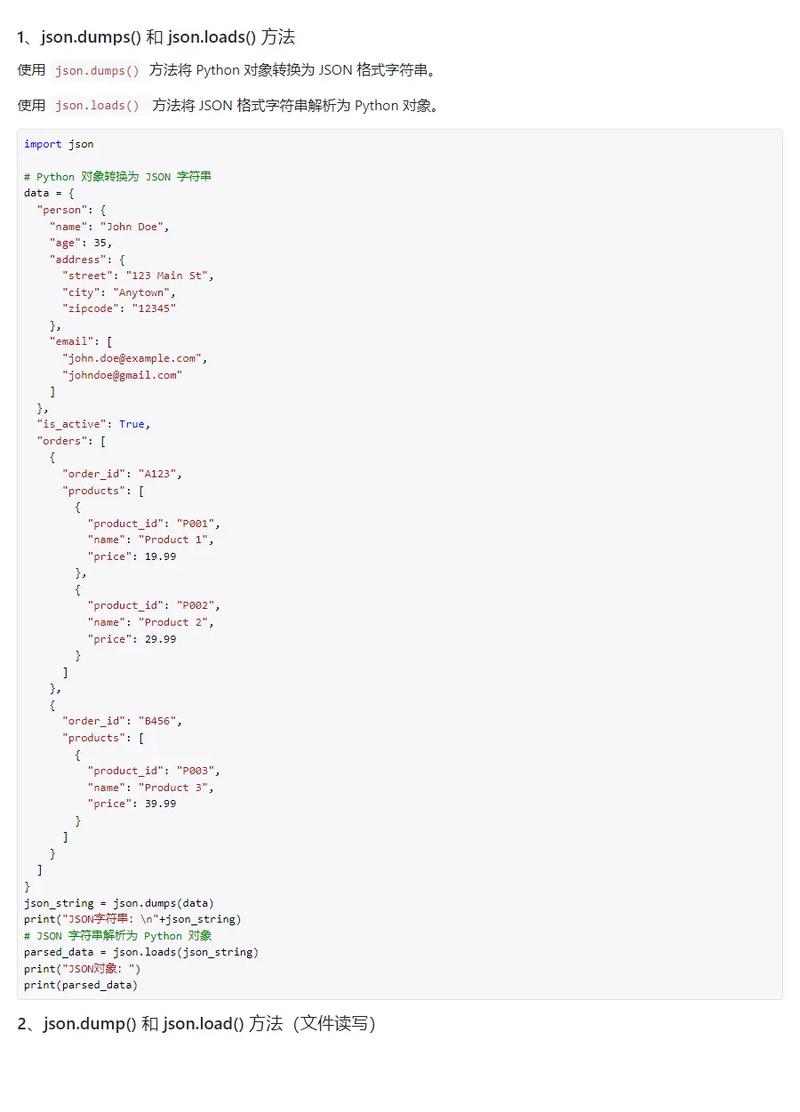
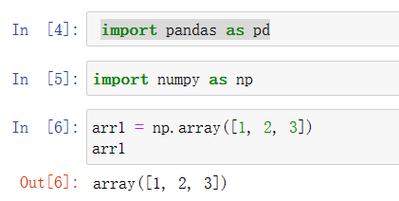
```python
import pandas as pd
导入CSV文件
df = pd.read_csv('data.csv')
导出CSV文件
df.to_csv('output.csv', index=False)
数据清洗与预处理

数据清洗和预处理是数据处理的要害步骤,它包含以下使命:
- 缺失值处理:辨认和处理数据中的缺失值。
- 异常值检测:辨认和处理数据中的异常值。
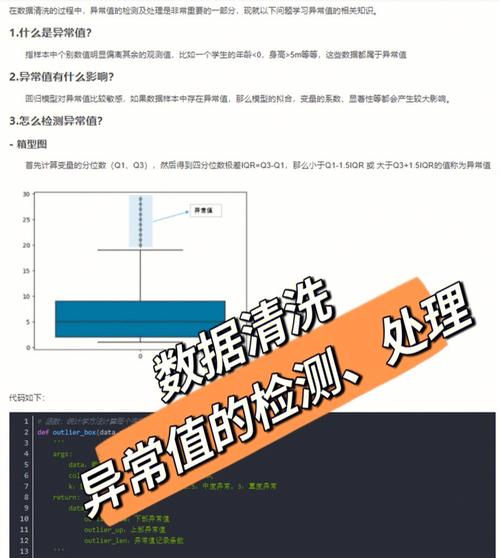
- 数据转化:将数据转化为合适剖析的方式。

```python
处理缺失值
df.fillna(method='ffill', inplace=True)
检测异常值
q1 = df['column'].quantile(0.25)
q3 = df['column'].quantile(0.75)
iqr = q3 - q1
lower_bound = q1 - 1.5 iqr
upper_bound = q3 1.5 iqr
df = df[(df['column'] >= lower_bound)
未经允许不得转载:全栈博客园 » python数据处理, 挑选适宜的Python库
 核算机二级python,轻松应对,顺畅通关
核算机二级python,轻松应对,顺畅通关 在线运转c言语,快捷编程体会的新挑选
在线运转c言语,快捷编程体会的新挑选 电动go,绿色出行新挑选,未来出行新趋势
电动go,绿色出行新挑选,未来出行新趋势 java面向目标的三大特性,Java面向目标的三大特性详解
java面向目标的三大特性,Java面向目标的三大特性详解 go与go to的差异,深化解析“go”与“go to”的差异
go与go to的差异,深化解析“go”与“go to”的差异 java项目实例,Java项目实例——简易在线图书办理体系
java项目实例,Java项目实例——简易在线图书办理体系 java游戏模仿器,重温经典游戏的利器
java游戏模仿器,重温经典游戏的利器










