
 全栈博客园
全栈博客园开源数据仓库:大数据年代的利器

跟着大数据年代的到来,企业关于数据存储和剖析的需求日益增长。开源数据仓库作为一种灵敏、本钱效益高的解决方案,受到了广泛的重视。本文将介绍开源数据仓库的概念、优势以及干流的开源数据仓库解决方案。
一、什么是开源数据仓库?
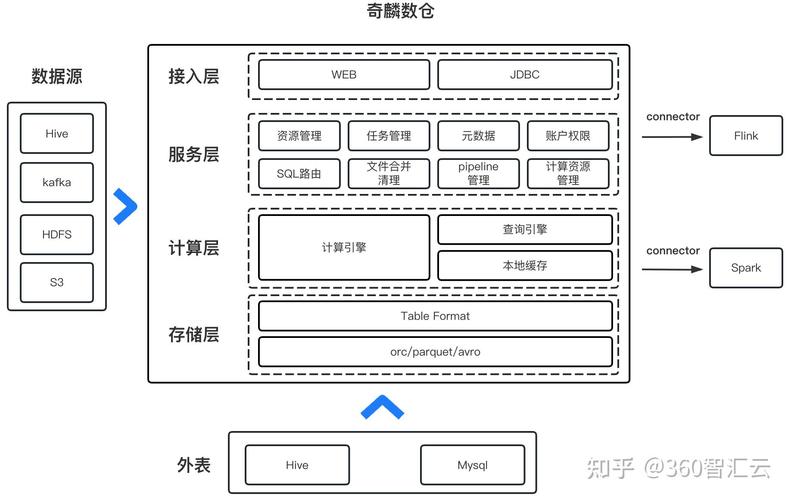
开源数据仓库是指依据开源协议发布的数据仓库软件。它答使用户免费运用、修正和分发,一起社区供给技能支撑和文档。开源数据仓库的中心优势在于其灵敏性和本钱效益,用户能够依据自己的需求进行定制和优化。
二、开源数据仓库的优势
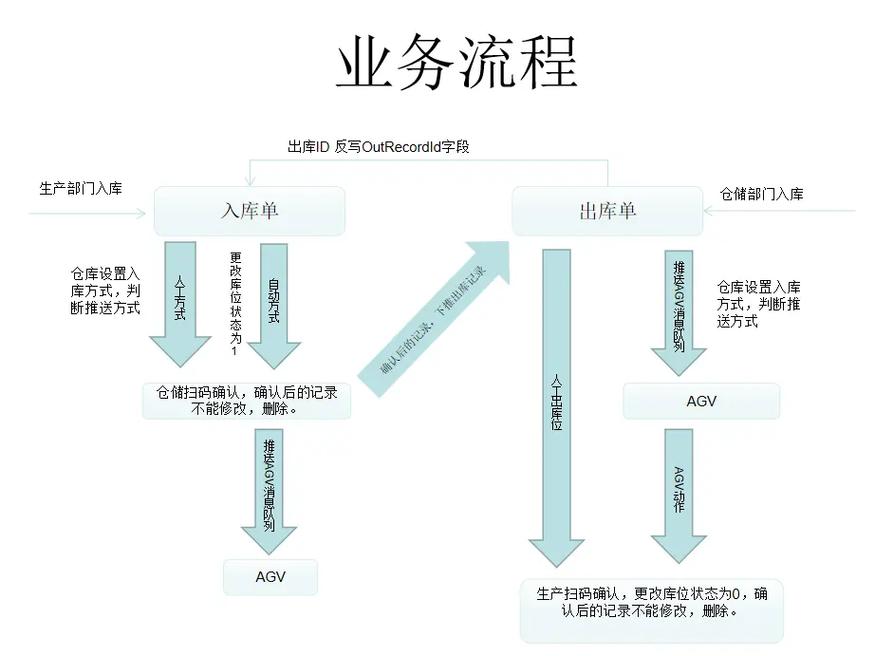
1. 本钱效益:开源数据仓库软件免费运用,降低了企业的软件本钱。
2. 灵敏性:用户能够依据自己的需求进行定制和优化,满意特定事务场景。
3. 社区支撑:开源项目具有巨大的社区,用户能够获取技能支撑和文档。
4. 技能创新:开源项目鼓舞技能创新,不断推进数据仓库技能的开展。
三、干流开源数据仓库解决方案
1. Apache Hadoop Hive
Apache Hadoop Hive是一个建立在Hadoop之上的数据仓库东西,供给了一种相似SQL的查询言语HQL。Hive适用于处理PB级数据,具有易用性和扩展性。Hive的查询推迟较高,不适合实时查询。
2. Apache Spark SQL
Apache Spark SQL是Apache Spark的一部分,支撑SQL查询、DataFrame以及RDD。Spark SQL使用内存核算,明显提高数据处理速度,兼容性强,易于与其他Spark组件集成。但Spark SQL的学习曲线相对较峻峭。
3. ClickHouse
ClickHouse是一款高功能的开源列式存储数据库,适用于在线剖析处理(OLAP)场景。ClickHouse具有高并发、低推迟、可扩展性强等特色,但相对较新的技能,社区支撑或许不如其他老练的开源项目。
4. Greenplum
Greenplum是一款依据PostgreSQL的开源数据仓库,具有高功能、可扩展性等特色。Greenplum适用于大规模数据仓库场景,但相对较重的系统资源耗费或许成为其使用的瓶颈。
5. Apache Druid
Apache Druid是一款开源的实时剖析数据库,适用于实时查询和剖析场景。Druid具有高并发、低推迟、可扩展性强等特色,但相对较新的技能,社区支撑或许不如其他老练的开源项目。
开源数据仓库在当时大数据年代具有广泛的使用远景。企业能够依据自己的事务需求和预算挑选适宜的数据仓库解决方案。在挑选开源数据仓库时,应考虑其易用性、功能、可扩展性、社区支撑等要素。跟着技能的不断开展,开源数据仓库将为大数据年代的企业供给愈加高效、快捷的数据存储和剖析服务。
 c开源项目,探究C言语开源项目的魅力与价值
c开源项目,探究C言语开源项目的魅力与价值 开源crm体系,助力企业高效办理客户关系
开源crm体系,助力企业高效办理客户关系 银澎云核算,引领云视频会议新时代
银澎云核算,引领云视频会议新时代 区块链电子钱包,未来金融付出的革新者
区块链电子钱包,未来金融付出的革新者 区块链介绍ppt,区块链简介
区块链介绍ppt,区块链简介 百度云核算中心,引领未来核算年代的引擎
百度云核算中心,引领未来核算年代的引擎












